공간 패턴 분석을 수행하면 인지하지 못했던 특성을 파악하거나 어떤 주장에 대한 명확한 근거를 수집할 수 있습니다. 이는 값의 분포, 위치의 공간적 배열을 모두 고려하기 때문에 패턴을 직관적으로 나타낼 수 있습니다.
패턴 분석은 표본 관측치를 기반으로 형상이나 값에 따른 농도를 강조하여 영역을 표시할 수 있습니다. 또한 통제 집단과 실험 집단을 선정하여 현상이나 사건에 대한 영향을 비교함으로써 특성을 도출하도록 지원합니다.
따라서 공간 패턴 분석을 통해 데이터 셋의 집중도 정도를 포함하는 영역을 식별할 수 있으며 패턴이 더욱 명확하게 시각화될 수 있습니다. 데이터 분포의 특성을 이해하면 가설이나 결과에 대한 이성적인 도출을 가능하게 합니다.
공간 패턴을 이해하면 다음과 같은 유형의 질문에 대한 답을 찾을 수 있습니다 🙂
- 사건의 밀도가 가장 높은 곳은 어디입니까?
- 발생한 현상의 밀집 정도는 어떻습니까?
- 발생한 사건에 규칙이나 특이점이 있습니까?
- 어떤 영역이 위험합니까?
이번 테크스토리에서 준비한 실습은 시간, 위치, 사상자 정보를 포함하는 교통사고 데이터를 이용한 공간 패턴 분석을 수행하려고 합니다. 미국에 있는 A 지역에서 2010년 01월 01일부터 2015년 12월 31일까지 6년간 교통사고가 빈번하게 발생한 장소와 시기를 파악해 위험 지역을 식별하여 예방하려고 합니다. 자, 그럼 시작해볼까요?
[Training : Analyzing traffic accidents in space and time]
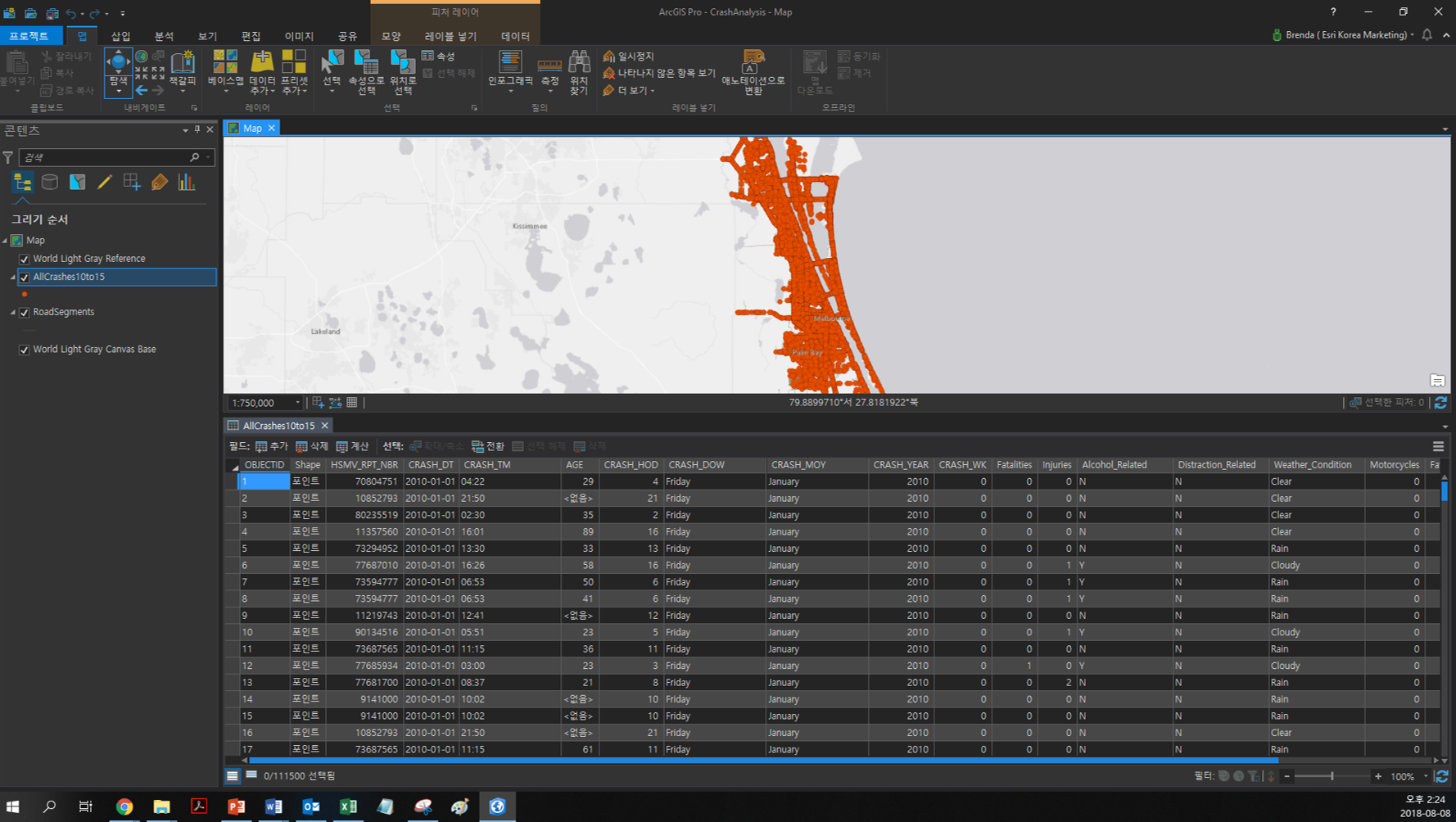
☞ 데이터 불러오기
CrashAnalysis 패키지 파일은 충돌 일자, 시간, 사상자 수, 날씨 정보 등을 포함합니다.
☞ 시공간 큐브 및 핫스팟 생성
[포인트를 집계하여 시공간 큐브 생성(Create Space Time Cube By Aggregating Points)]
핫스팟 분석을 수행하기 위해 시공간 큐브를 생성합니다. 포인트를 집계해 시공간 큐브를 생성하는 도구는 netCDF 데이터 구조로 시공간 저장소에 요약합니다.
- 입력 피처(Input Features) : AllCrashes10to15
- 결과 시공간 큐브(Output Space Time Cube) : 사용자 지정 ex)AllCrashes.nc
- 시간 필드(Time Field) : CRASH_DT
- 시간 단계 간격(Time Step Interval) : 16주
- 시간 단계 정렬(Time Step Alignment) : 종료 시간
- 거리 간격(Distance Interval) : 2마일
- 집합 모양 유형(Aggregation Shape Type) : 육각형 그리드
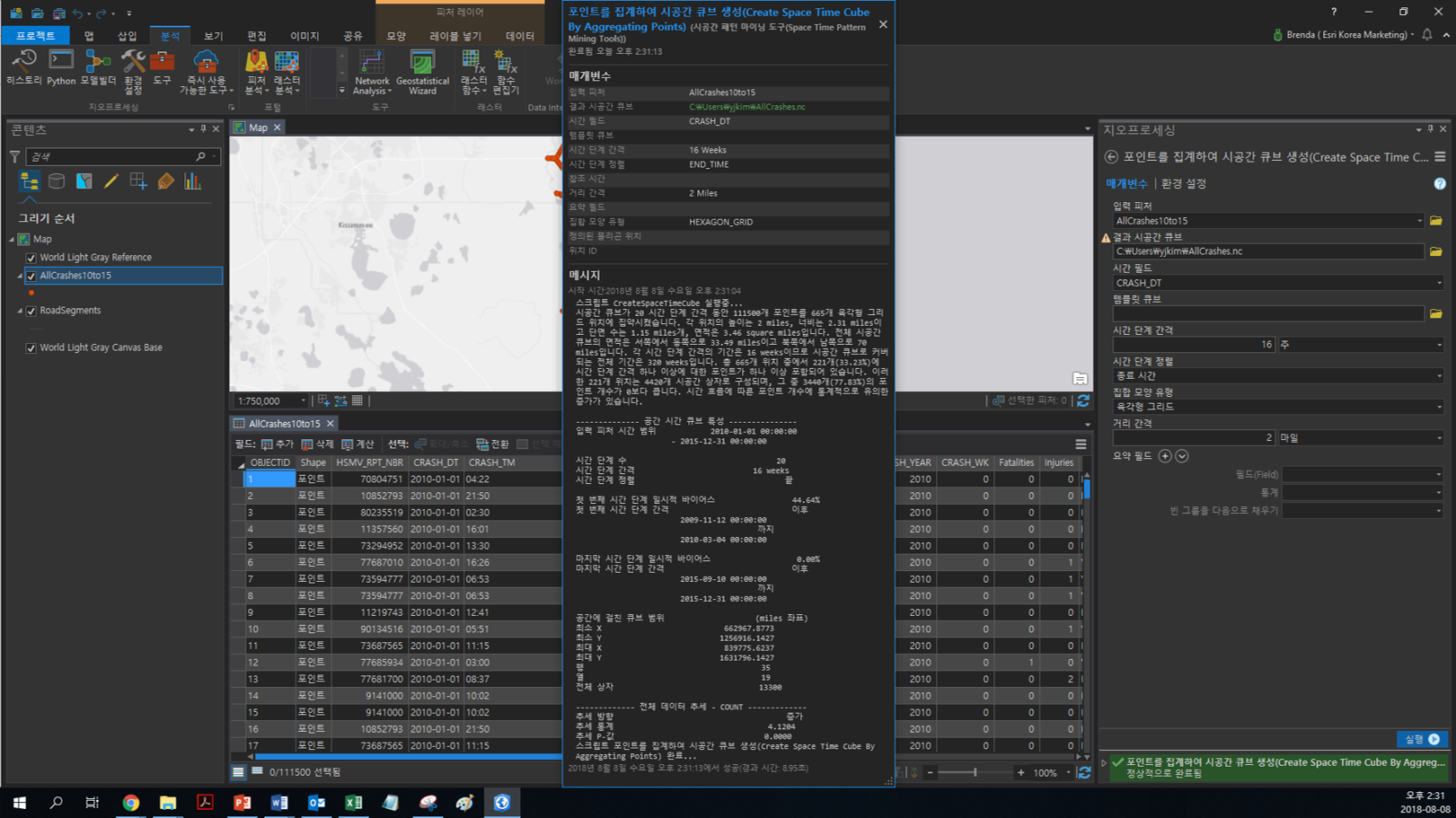
결과 메시지를 확인해볼까요? 총 665개 위치 중 221개(33.23%)에 16주 간격으로 포인트가 하나 이상 포함되어 있으며 충돌의 추세가 증가하고 있음을 알 수 있습니다.
[발생 핫스팟 분석(Emerging Hot Spot Analysis)]
생성한 시공간 큐브를 사용하여 발생 핫스팟 분석을 수행합니다. 이때 네이버후드 거리 및 시간 단계는 기본값을 사용하고, 나머지 매개변수는 아래와 같이 입력합니다.
- 입력 시공간 큐브(Input Space Time Cube) : AllCrashes.nc
- 분석 변수(Analysis Variable) : COUNT
- 결과 피처(Output Features) : 사용자 지정 ex)AllCrashes.nc
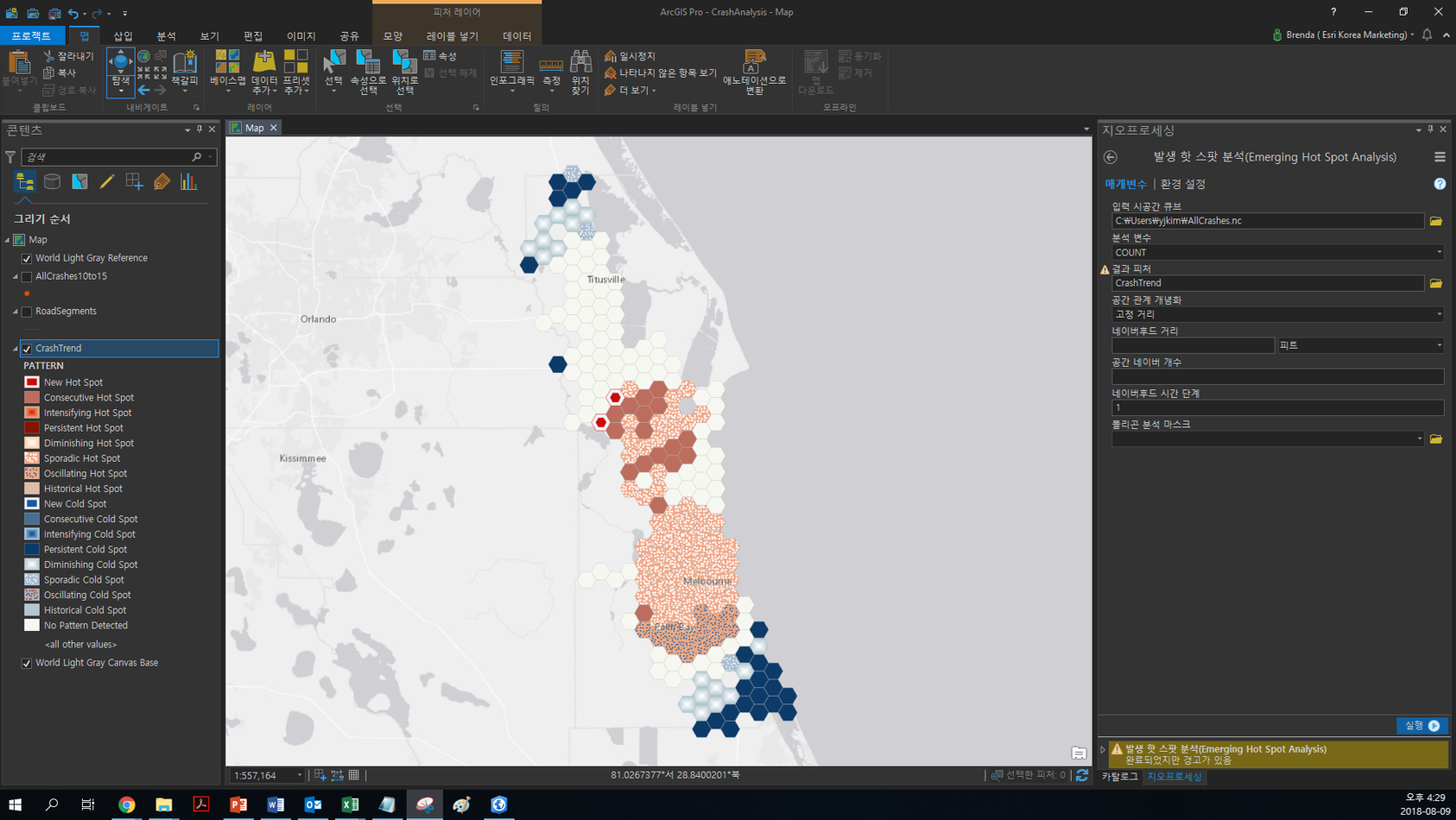
결과창에는 새로운 핫/콜드스팟, 연속 핫/콜드스팟 등을 포함한 17개의 패턴을 나타내며, 실행 결과에서 표시되는 메시지는 기본값으로 정의한 네이버후드의 정보를 제공하고 있으니 확인해주세요.
☞ 도로망 충돌 핫스팟 생성
이번 단계에서는 스냅 도구를 사용해 충돌 포인트를 도로망 라인에 일치시킬 것입니다. 먼저 스내핑하기 전에 피처 복사를 수행하여 도로에 연결할 포인트를 복사해주세요.
[피처 복사(Copy Feature)]
- 입력 피처(Input Feature): AllCrashes10to15
- 결과 피처 클래스(Input Feature Class): 사용자 지정 ex) Crash_Points
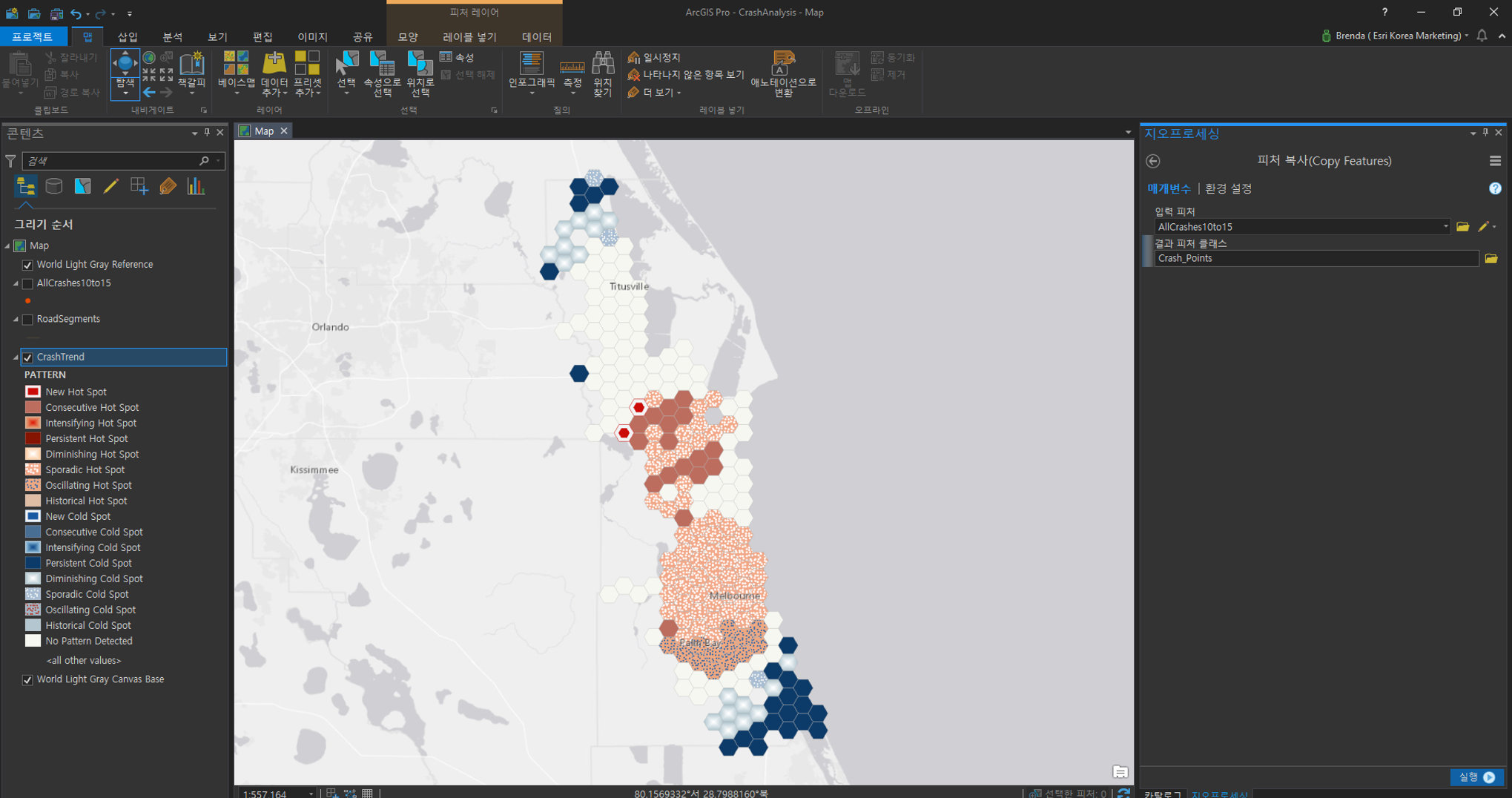
[스냅(Snap)]
- 입력 피처(Input Features) : Crash_Points
- 스냅 환경(Snap Environment)
– 피처(Features) : RoadSegments
– 유형(Type) : 엣지(Edge)
– 거리(Distance) : 0.25마일
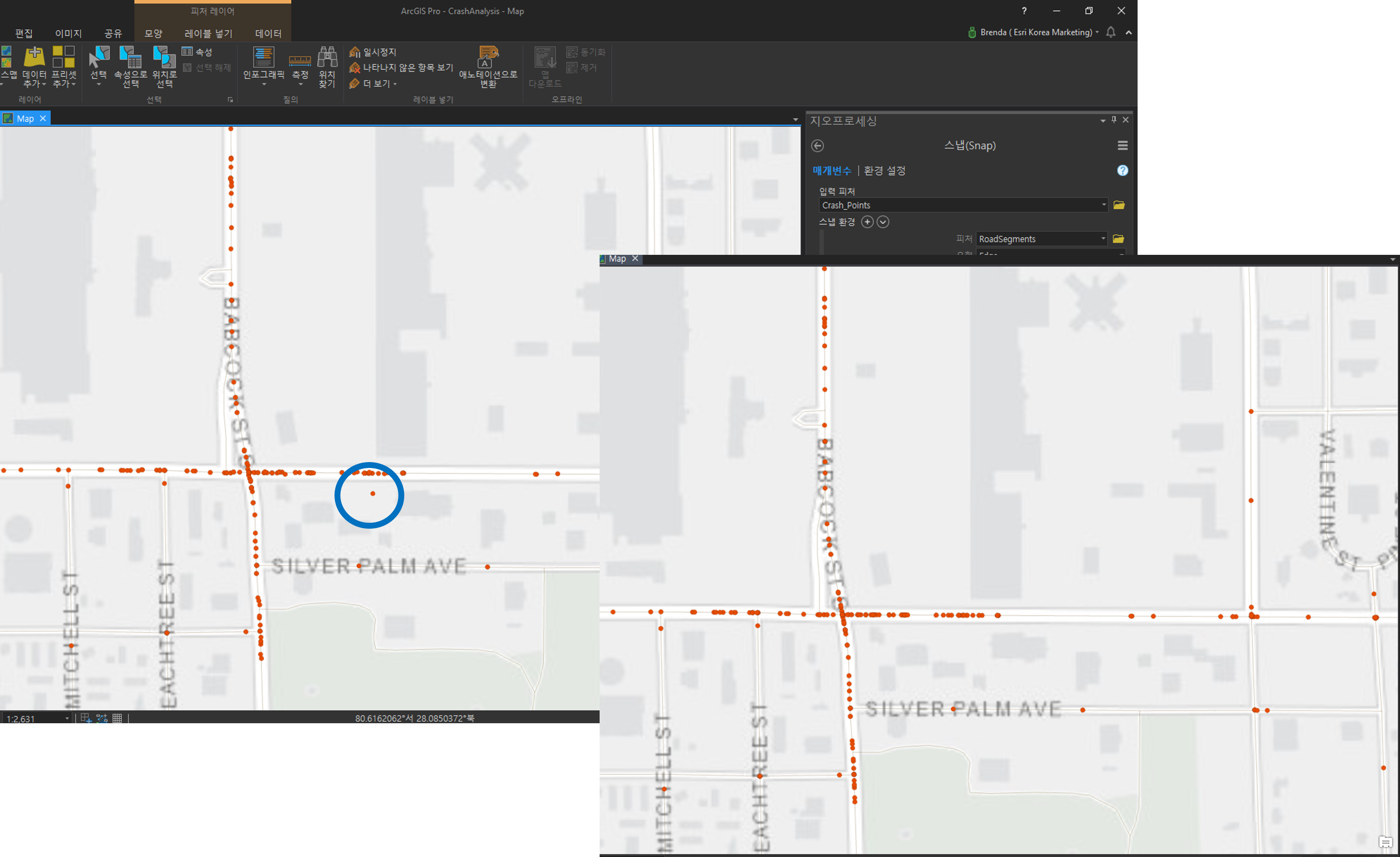
좌측 그림에서 포인트가 도로 데이터 바깥에 위치하는 것을 볼 수 있는데요, 스냅 도구를 사용한 후 포인트가 도로 데이터에 매치된 것을 우측 그림에서 확인할 수 있습니다.
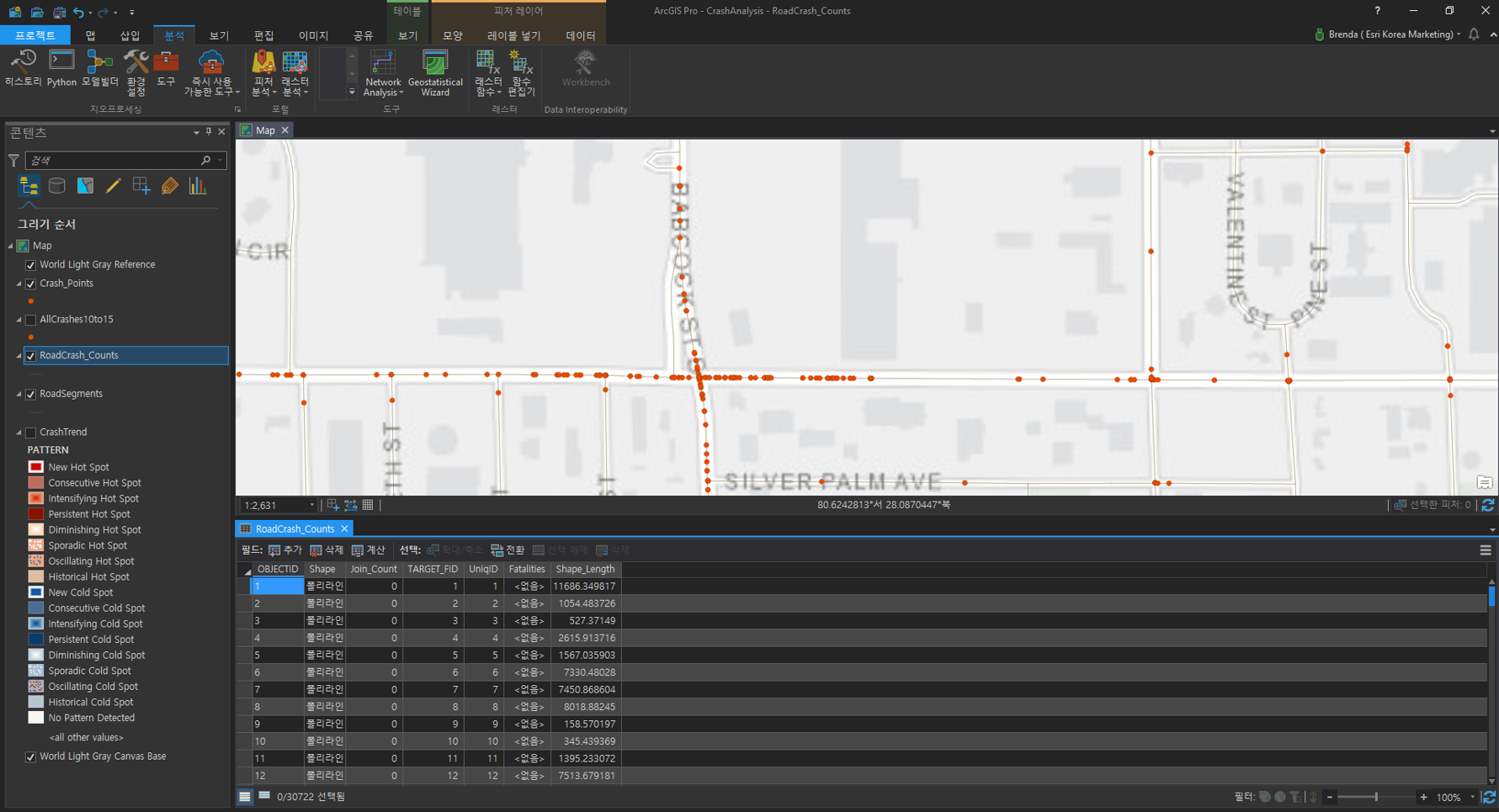
[공간 조인(Spatial Join)]
공간 도구를 사용하여 각 도로의 구간에서 발생한 사고 발생수를 계산할 수 있습니다. 공간 조인 시 제거하려는 필드 위에 마우스를 가져가면 X표시가 나타나는데, 이때 분석에 필요한 UniqID 및 Fatalities를 제외한 나머지 필드를 제거해주세요.
- 대상 피처(Target Features) : RoadSegments
- 조인 피처(Join Features) : Crash_Points
- 결과 피처 클래스(Output Feature Class) : 사용자 지정 ex) RoadCrash_Counts
- 조인 피처의 필드 맵(Field Map of Join Features) : UniqID, First; Fatalities, Sum
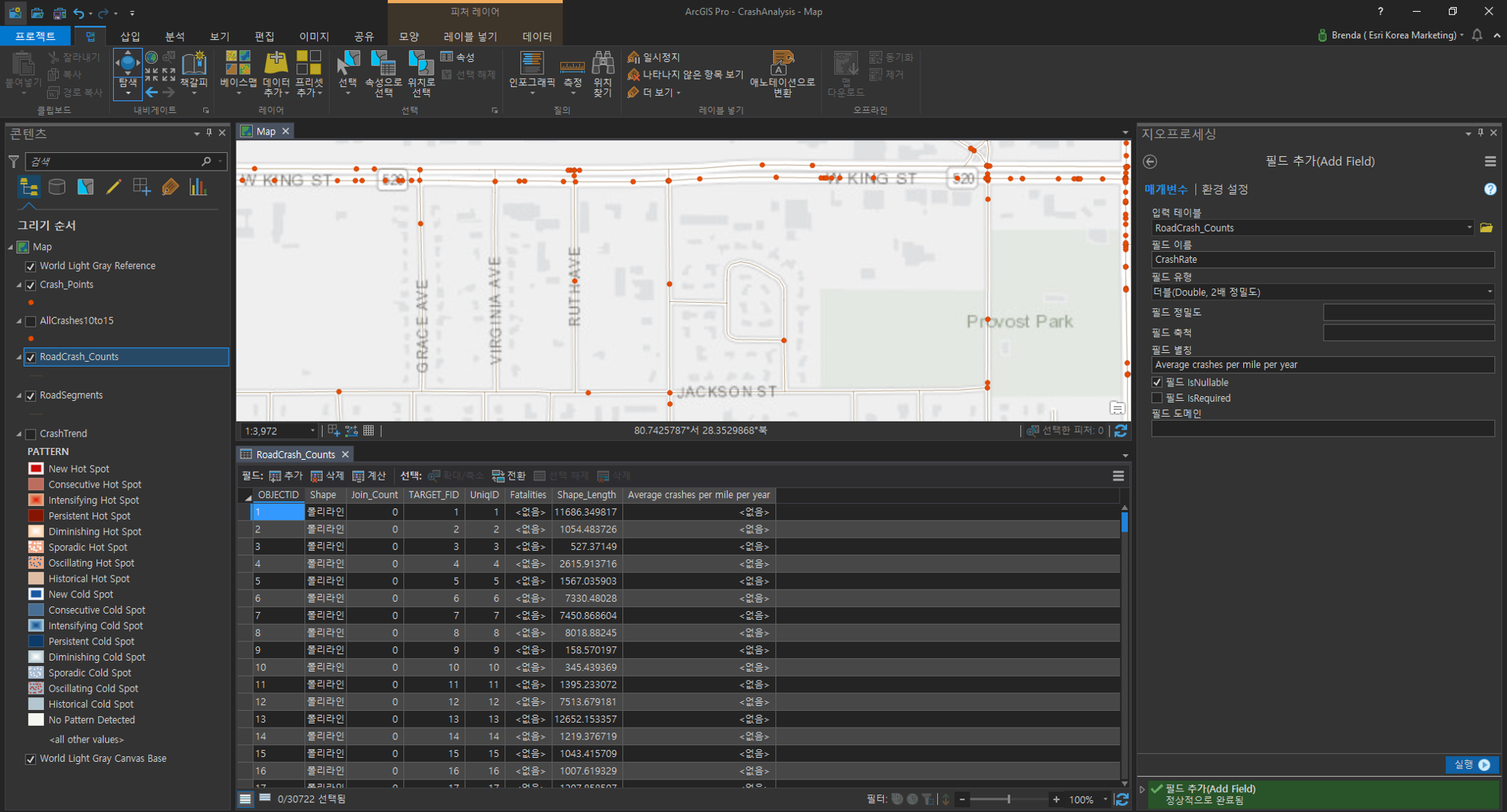
[필드 추가(Add Field)]
각 도로 구간에 대해 거리/시간에 따른 충돌률은 필드 추가 및 계산 도구를 이용하여 산출합니다.
- 입력 테이블(Input Table) : Road_Crash_Counts
- 필드명(Field Name) : CrashRate
- 필드 유형(Field Type) : Double
- 필드 별칭(Field Alias) : Average crashes per mile per year
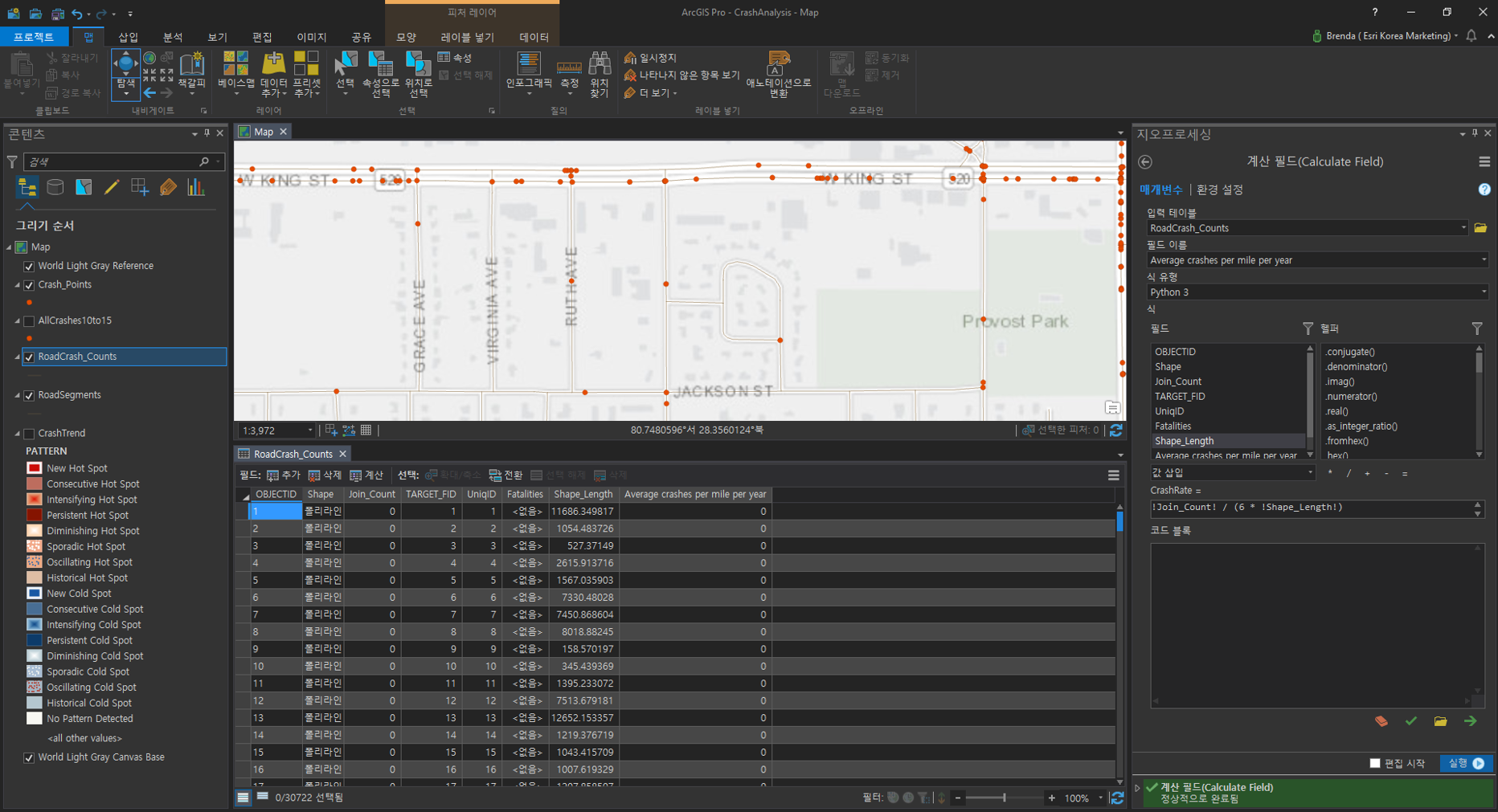
[필드 계산(Calculate Field)]
각 구간에서 발생한 충돌률은 발생한 포인트 수를 거리로 나눠 계산합니다. 단, 충돌 포인트는 6년 동안 수집했으므로 거리에 6을 곱해줍니다.
- 입력 테이블(Input Table) : Road_Crash_Counts
- 필드명(Field Name) : Average crashes per mile per year
- 식(Expression) : !Join_Count! / (6 * !Shape_Length!)
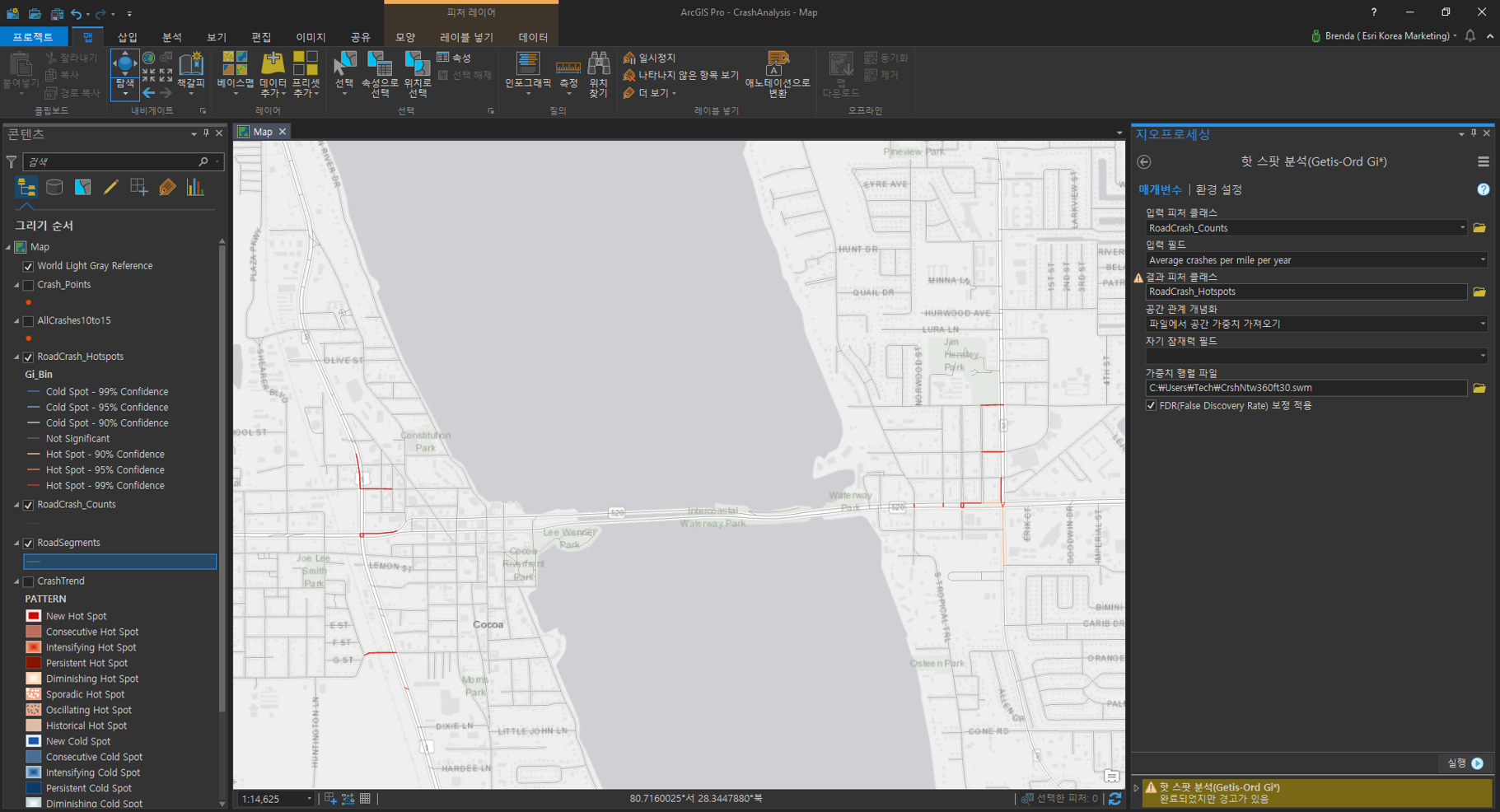
[핫스팟 분석(Hot Spot Analysis(Getis-Ord Gi*))]
필드가 생성됐으면 충돌률에 대한 핫스팟 분석을 수행합니다. 이때 가중치 행렬 파일에 입력되는 CrshNtw360ft30.swm 파일은 다운받은 폴더에 위치해있습니다.
- 피처 클래스 입력(Input Feature Class) : Road_Crash_Counts
- 입력 필드(Input Field) : Average crashes per mile per year
- 결과 피처 클래스(Output Feature Class) : 사용자 지정 ex) RoadCrash_HotSpots
- 공간 관계 개념화(Conceptualization of Spatial Relationships) : 파일에서 공간 가중치 가져오기(Get spatial weights from file)
- 가중치 행렬 파일(Weights Matrix File) : CrshNtw360ft30.swm
- Apply False Discovery Rate (FDR) 보정 적용 체크
핫스팟 분석 결과는 통계적으로 90% 신뢰구간, 95% 신뢰구간, 99% 신뢰구간을 산출하여 나타내며, 이를 통해 A 지역의 도로망에서 충돌률이 높은 구간을 확인할 수 있습니다. 참고로 좌표계가 다르다는 경고는 해당 분석에는 영향을 미치지 않으니 무시하셔도 무방합니다.
☞ 데이터를 차트로 시각화
[선형 차트 생성(Create Line Chart)]
지금까지 충돌 데이터를 이용한 사고 동향 및 빈도를 핫스팟으로 분석해봤습니다. 마지막으로 어느 시간대에 사고가 가장 빈번하게 발생했는지 선형 차트를 통해 알아보겠습니다.
- AllCrashes10to15 레이어 → 차트 생성(Create Chart) → 선형 차트(Line Chart) 클릭
- 차트(Chart)창 매개변수
– 날짜 또는 숫자(Date or Number) : CRASH_HOD
– 집계(Aggregation) : 개수
– 시리즈(Data series) : 시리즈로 분할된 하나의 필드를 통해(From one field split into series)
– 분할 기준(Split by) : CRASH_DOW
- 일반(General)탭 매개변수
– 차트 제목(Chart title) : Traffic Accidents
– X축(X axis title) : Hour of the Day (24 hour clock)
– Y축(Y axis title) : Number of Crashes
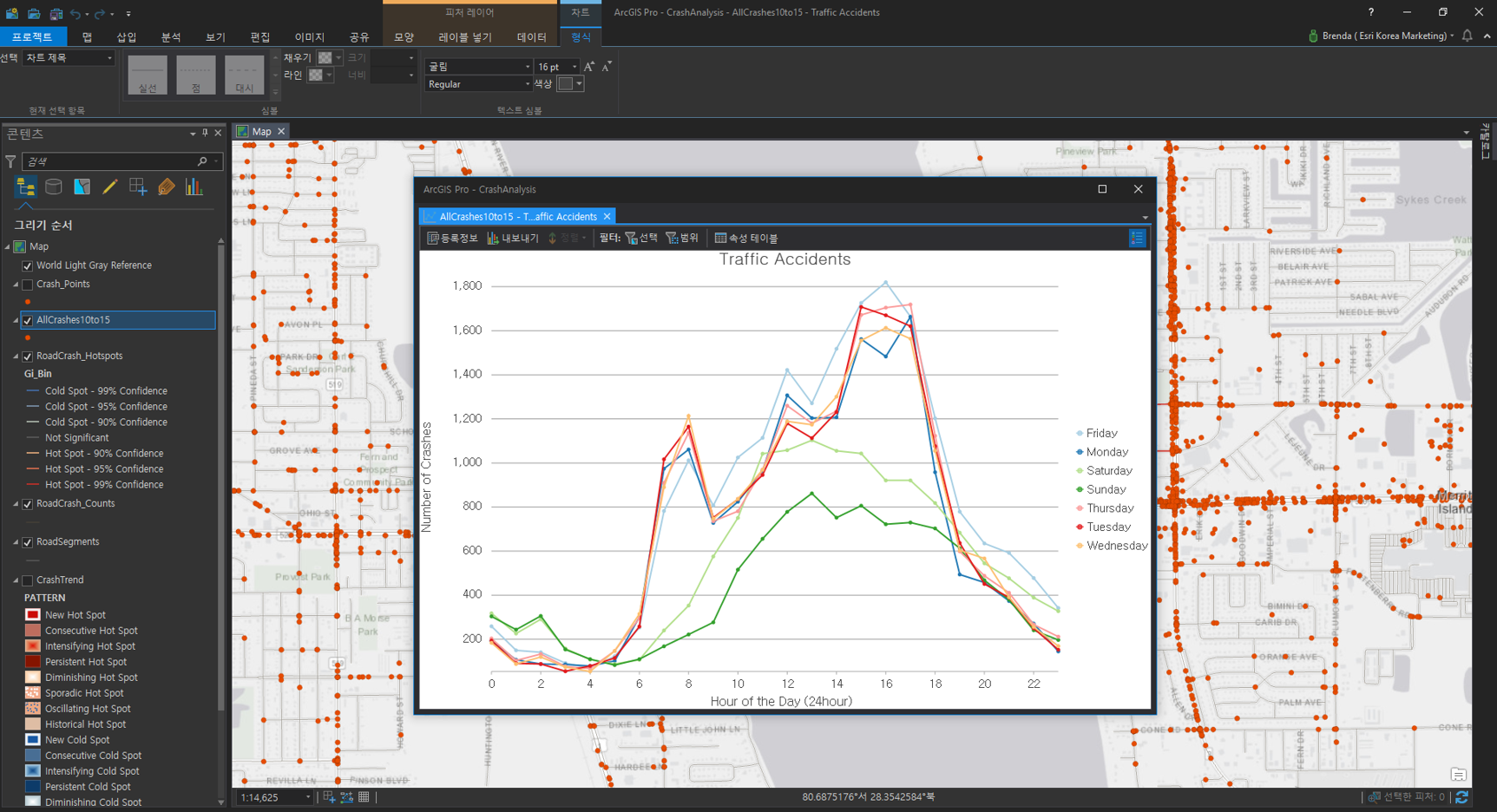
생성된 선형 차트는 시간대에 따른 교통사고 발생 수를 시각화한 결과로 오후 3시부터 5시까지 충돌이 가장 많이 발생한 것을 확인할 수 있습니다.
이번 실습에서는 핫스팟 분석을 이용한 충돌 사고 동향 및 충돌률 패턴 분석을 수행하고, 사고 발생 빈도를 선형 차트로 시각화하여 결과를 확인해봤습니다. 이처럼 ArcGIS Pro는 동일한 데이터를 이용하여 분석 목적에 따른 적절한 방법을 선정하고 수행할 수 있도록 지원합니다. 다음 실습에서는 핫스팟 분석 결과를 3차원으로 시각화하는 방법을 소개해드릴 예정이니 기대해주세요 🙂
연관 게시물 바로 가기
[ArcGIS Pro 완전 정복!] ①입문
[ArcGIS Pro 완전 정복!] ②기본
[ArcGIS Pro 완전 정복!] ③실전: 공유하기
[ArcGIS Pro 완전 정복!] ④분석: 위치에 대한 이해
[ArcGIS Pro 완전 정복!] ⑤분석: 데이터의 관계성을 이용한 분석
[ArcGIS Pro 완전 정복!] ⑥분석: 입지분석
[ArcGIS Pro 완전 정복!] ⑦분석: 고도 데이터를 이용한 가시권 분석
[문의] 한국에스리 02)2086-1960
[참고자료] Esri, Analyzing traffic accidents in space and time