
‘청년 실업률’이 연일 큰 화두로 떠오르고 있습니다. 지난해 청년실업률은 9.8%를 기록하며 1999년 통계기준 변경 이후 최고치를 달성하기도 했는데요, 사실 실업문제는 비단 한국만이 아닌 전 세계의 공통 관심사가 된지 오래입니다.
실업률이 계속되면 사회적으로 어떤 영향을 미치게 될까요? 최근에는 높은 실업률로 야기될 수 있는 각종 사회문제에도 관심이 많아지고 있습니다. 특히 범죄학 분야에서는 경기침체나 실업률의 변화가 범죄발생에 끼치는 영향을 오랫동안 주시해왔는데, 공간 분석을 통해 실업률과 범죄의 상관관계를 알아볼 수 있습니다.
공간 분석은 주로 과거에 발생한 사건 및 현상에 대해 원인을 찾고 결과를 분석하는 데 사용되고 있습니다. 하지만 위치 정보가 있는 공간 데이터를 이용하면 미래에 어떤 일이 일어날지 예측하고, 어떻게 대응할지 예방할 수도 있습니다.
예측과 예방을 어떻게 수행하는지 사례를 통해 알아볼까요?
A 지역의 범죄율이 전체적으로 감소했음에도 불구하고 유독 특정 구역에서만 지속해서 증가했습니다. A 지역의 경찰서장은 범죄율 증가에 대한 원인 및 해결 방안을 찾기 위해 데이터 분석가의 도움이 필요하다는 것을 느꼈습니다.
경찰서장은 분석가에게 여러 가지 공간 데이터를 제공하면서 범죄와 가장 강력한 상관관계를 가진 요인을 찾아 달라고 요청했습니다. 사건 발생 일자, 범죄 유형, 위치 정보를 포함한 범죄 데이터 외에도 공간적 상관관계 분석에 필요한 주류 판매점 위치, 빈곤율, 실업률 데이터가 제공됐습니다.
먼저 분석가는 범죄 데이터를 이용한 핫스팟 분석을 수행한 뒤 패턴 결과를 기반으로 심각하고 연속적인 범죄가 일어나는 지역을 파악합니다. 특히 범죄의 심각성과 발생 시간대를 나타내는 3D 시공간 큐브 데이터를 생성하여 동향을 살펴보고, 주류 판매점, 빈곤률, 실업률 데이터를 추가적으로 분석해 공간적 상관관계가 가장 높은 요인을 발견합니다.
자, 그럼 실습을 시작해봅시다!
[Training : Analyzing violent crime, workflow]
☞ 데이터 불러오기
먼저 Broken Bottle 패키지 파일을 불러옵니다. Violent Crime 2014 데이터의 속성 테이블을 열어 범죄 발생 지역의 분포, 범죄 유형, 일자를 확인합니다.
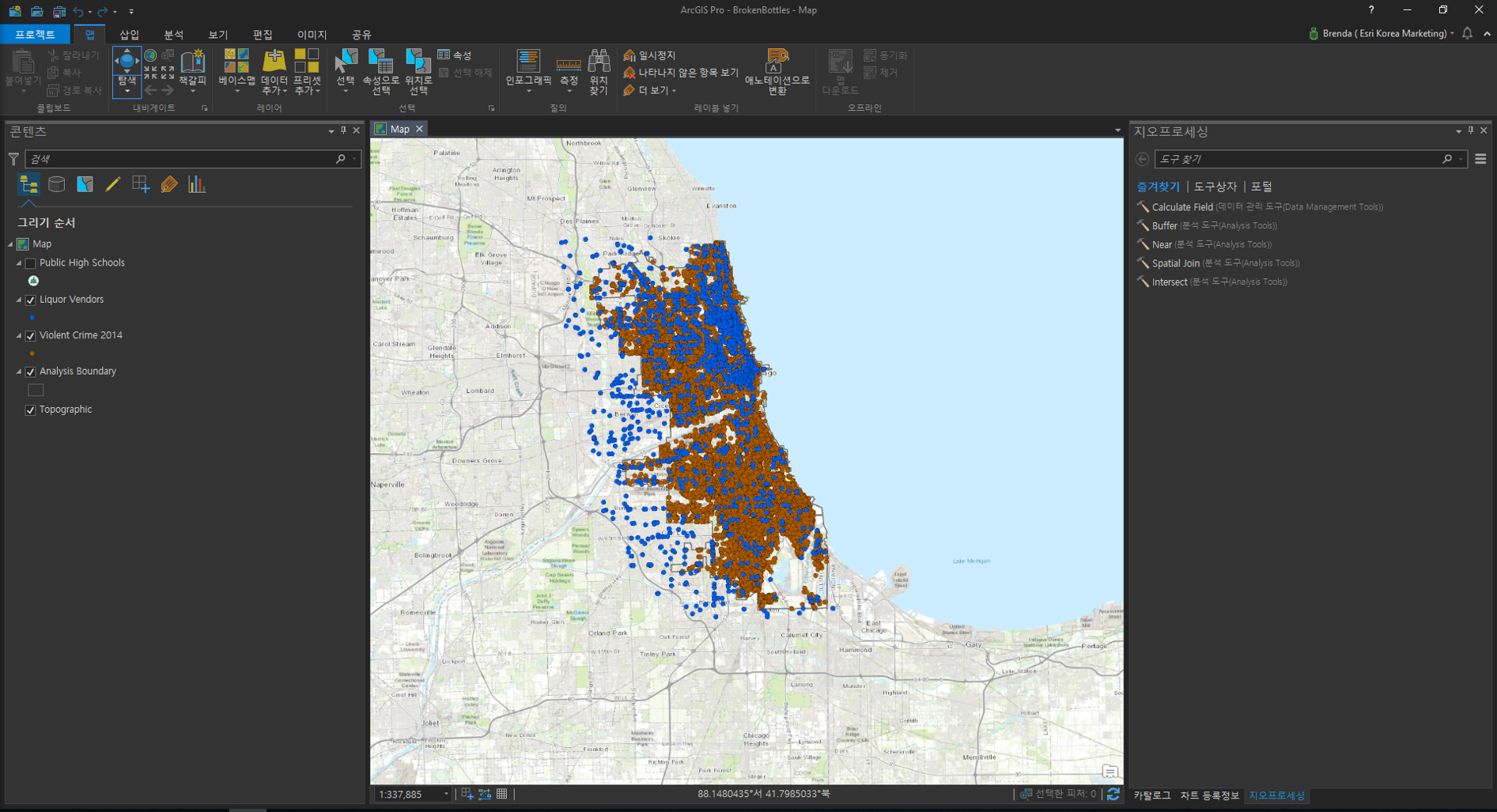
☞ 시공간 큐브 및 핫스팟 생성
범죄 발생 지역을 확인하고 패턴을 파악하기 위해 시공간 큐브 생성 및 핫스팟 분석을 수행합니다.
[포인트를 집계하여 시공간 큐브 생성(Create Space Time Cube By Aggregating Points)]
- 입력 피처(Input Feature): Violent Crime 2014
- 결과 시공간 큐브(Output Space Time Cube): 사용자 지정 ex)ViolentCrimeCube.nc
- 시간 필드(Time Field): Date
- 시간 단계 간격(Time Step Interval): 4주
- 시간 단계 정렬(Time Step Alignment): 종료 시간
- 거리 간격(Distance Interval): 1375 피트
[발생 핫스팟 분석(Emerging Hot Spot Analysis)]
- 입력 시공간 큐브(Input Space Time Cube): ViolentCrimeCube.nc
- 분석 변수(Analysis Variable): COUNT
- 결과 피처(Output Feature): 사용자 지정 ex)ViolentCrimeTrends
- 네이버후드 거리(Neighborhood Distance): 0.5 마일
- 네이버후드 시간 단계(Neighborhood Time Step): 1
- 폴리곤 분석 마스크(Polygon Analysis Mask):
- 분석 경계(Analysis Boundary)
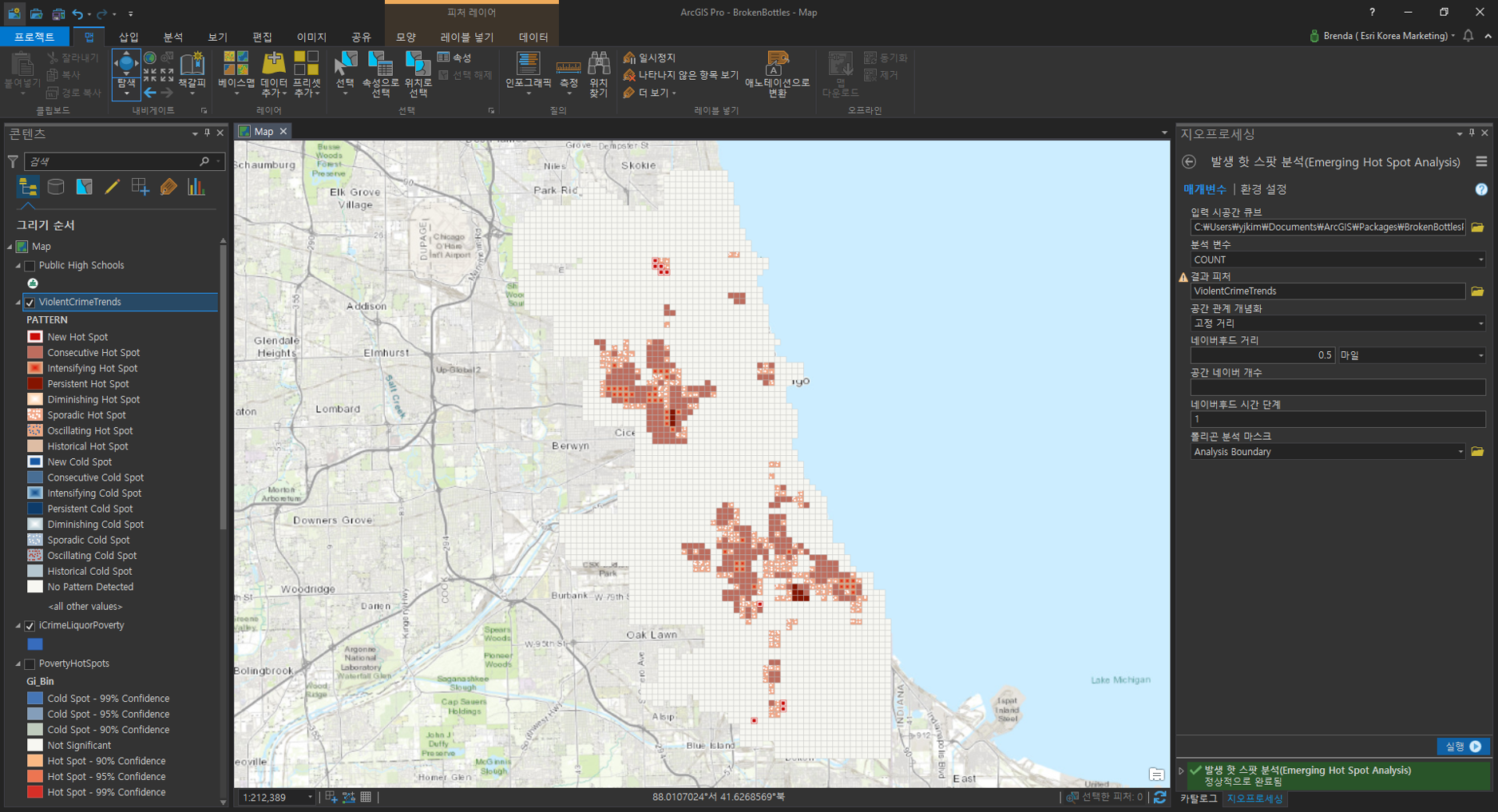
범죄 트랜드의 결과를 확인해보세요.
콜드스팟은 존재하지 않고 핫스팟만 존재하는 것을 알 수 있습니다. 이는 특정 지역의 범죄 밀도가 높은 것을 의미합니다. 또한 핫스팟 분석 결과를 통해 연속적이고 심각한 범죄가 발생한 지역을 파악할 수 있어 추가 범죄가 발생할 가능성이 있는 지역을 예측할 수 있습니다.
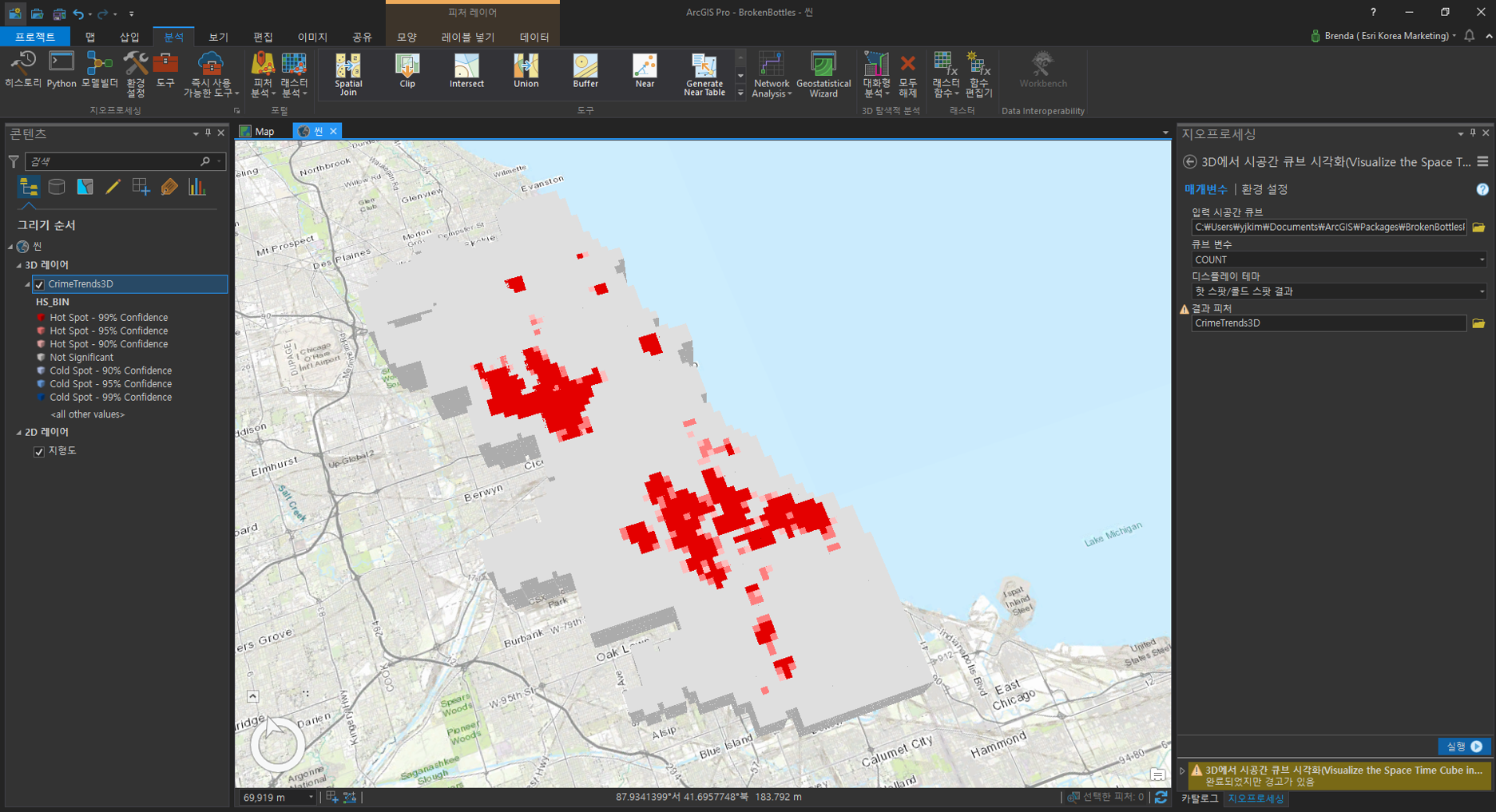
☞ 3D 시공간 큐브 시각화
범죄 심각성 및 발생 지역을 시간대별로 파악하기 위해 시공간 큐브를 생성하여 3D로 시각화합니다.
[새 씬 생성(Create New Scene)]
- 삽입(Insert) → 새 맵(New Map) 드롭다운 → 새 씬(New Scene) 클릭
[3D에서 시공간 큐브 시각화(Visualize the Space Time Cube in 3D)]
- 입력 시공간 큐브(Input Space Time Cube): Violent Crime Cube.nc
- 큐브 변수(Cube Variable): COUNT
- 디스플레이 테마(Display Theme): 핫스팟/콜드스팟 결과(Hot and cold spot results)
- 결과 피처(Output Features): CrimeTrends3D
[최적화된 핫스팟 분석(Optimized Hot Spot Analysis)]
베이스 맵과 작성한 데이터의 기준점이 다르므로 3D 큐브를 시각화하기 전 기존에 설정된 고도 원본을 삭제합니다.
- 씬 등록정보(Scene Properties) → 고도 표면(Elevation Surface) → 고도 원본(Ground) → 삭제(X) 아이콘 클릭
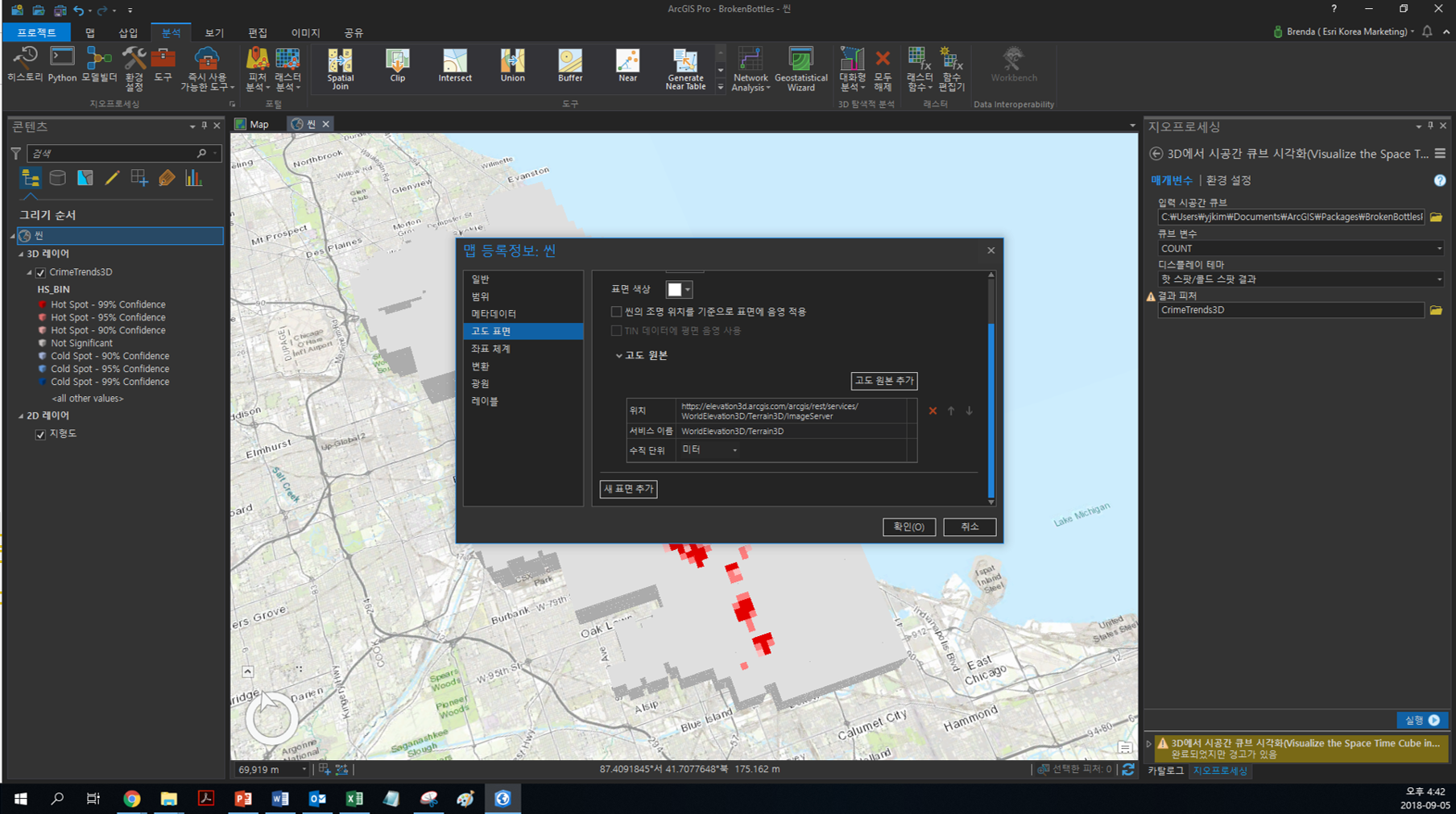
고도 원본을 삭제한 후 3D 시공간 큐브 결과를 탐색해보세요.
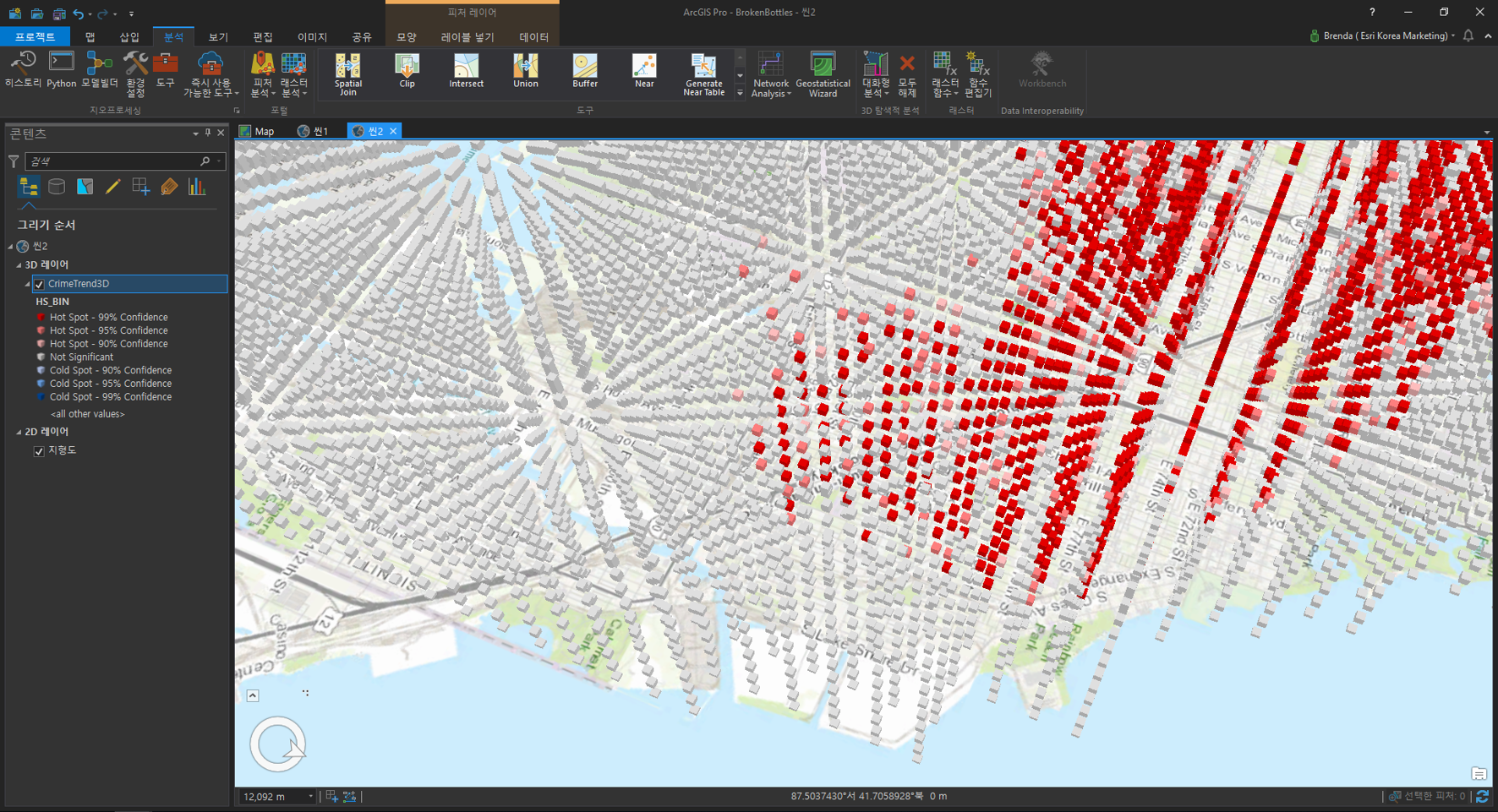
해당 결과는 시공간에 따른 범죄를 핫스팟, 콜드스팟, 90%, 96%, 99% 신뢰수준을 기반으로 3D 시공간 큐브를 나타냅니다.
☞ 범죄율 데이터, 주류 판매점 위치 데이터, 빈곤율 데이터를 이용한 핫스팟 생성
[최적화된 핫스팟 분석(Optimized Hot Spot Analysis)]
▶ 범죄율 데이터 이용
- 입력 피처(Input Features): Violent Crime 2014
- 결과 피처(Output Feature): 사용자 지정 ex) ViolentCrimeHotSpots
- 사건 데이터 집약 방법(Incident Data Aggregation Method): 그물망 그리드 내의 사건 계산(Count incidents within fishnet polygons)
- 사건 발생 가능 지역을 정의하는 경계 폴리곤(Bounding Polygons Defining Where Incidents Are Possible): 분석 경계(Analysis Boundary)
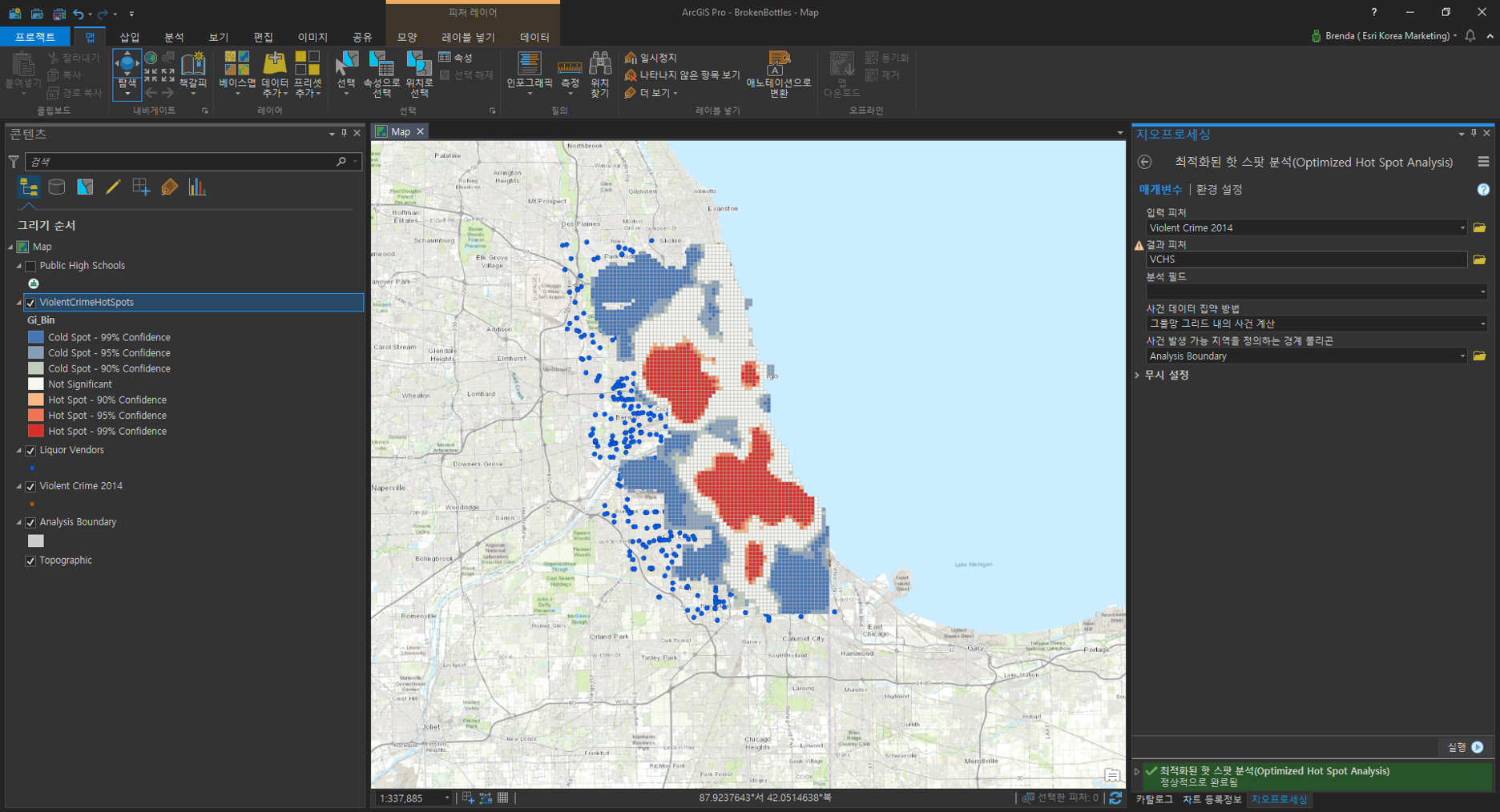
범죄 밀도에 따른 핫스팟을 생성하기 위해 Violent Crime 2014 데이터를 이용하며, 데이터 집계 방법 및 경계 폴리곤 등 매개변수를 설정합니다. 해당 도구에서 선정한 방법은 적절한 폴리곤의 셀 사이즈를 이용하는 ‘그물망 그리드 내 사건 계산’입니다. 연구 영역 내에 모든 핫스팟 데이터를 생성했으며, 결과 메시지를 통해 폴리곤의 셀 사이즈는 1375피트임을 알 수 있습니다.
▶ 주류 판매점 데이터 이용
- 입력 피처(Input Features): Liquor Vendors
- 결과 피처(Output Feature): 사용자 지정 ex) LiquorVendorHotspots
- 사건 데이터 집약 방법(Incident Data Aggregation Method): 집약 폴리곤 내 사건 계산(Count incidents within aggregation polygons)
- 사건 발생 가능 지역을 정의하는 경계 폴리곤(Bounding Polygons Defining Where Incidents Are Possible): ViolentCrimeHotSpots
빈곤 데이터를 이용한 핫스팟을 생성하기 전에 Poverty.lpk 파일을 맵에 불러와 핫스팟 데이터를 생성합니다.
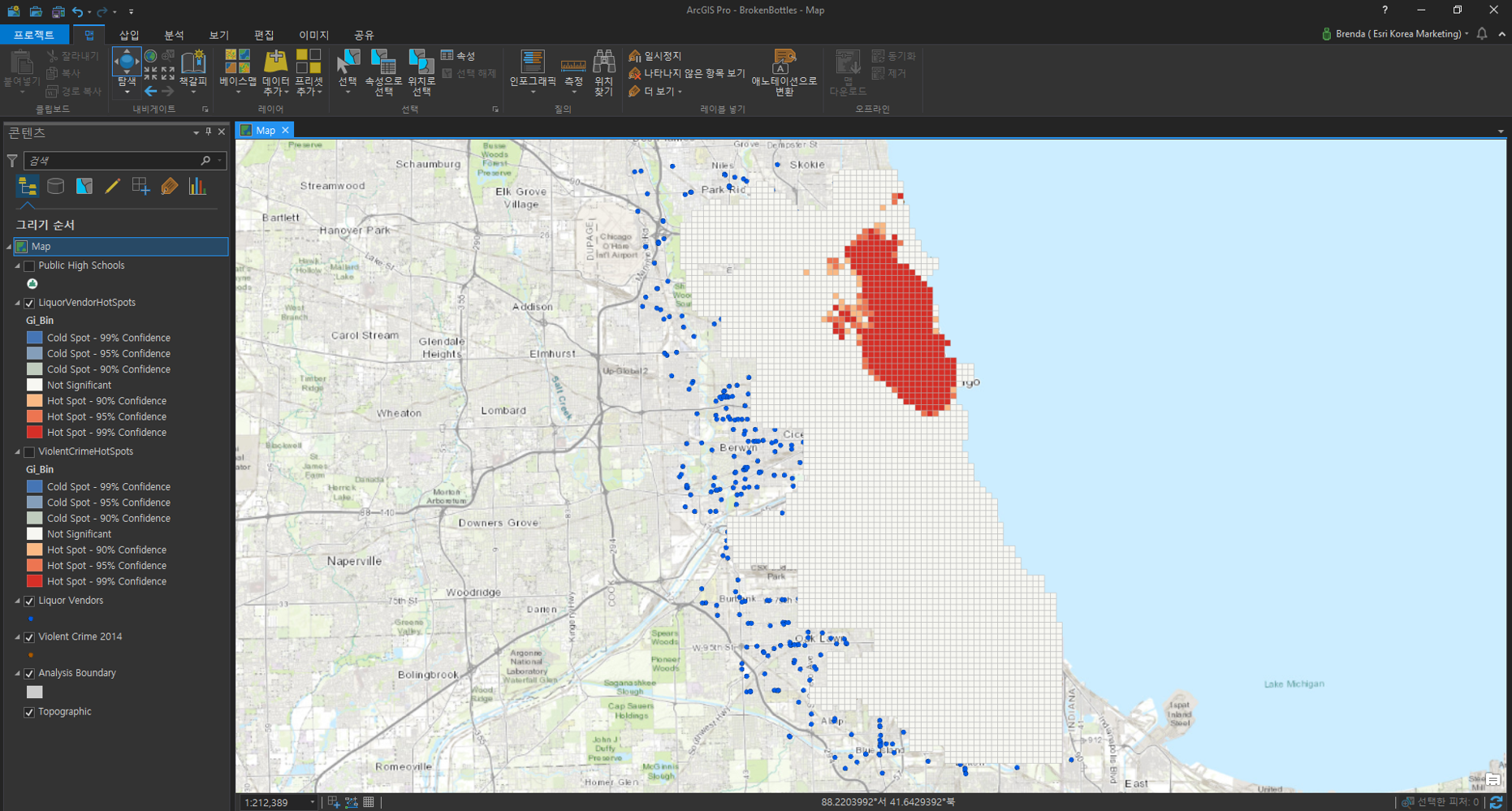
▶ 빈곤률 데이터 이용
집약 폴리곤 내 사건 계산 방법은 제공된 각각의 폴리곤 내에서 인시던트 포인트 데이터를 집계하여 결과를 도출합니다.
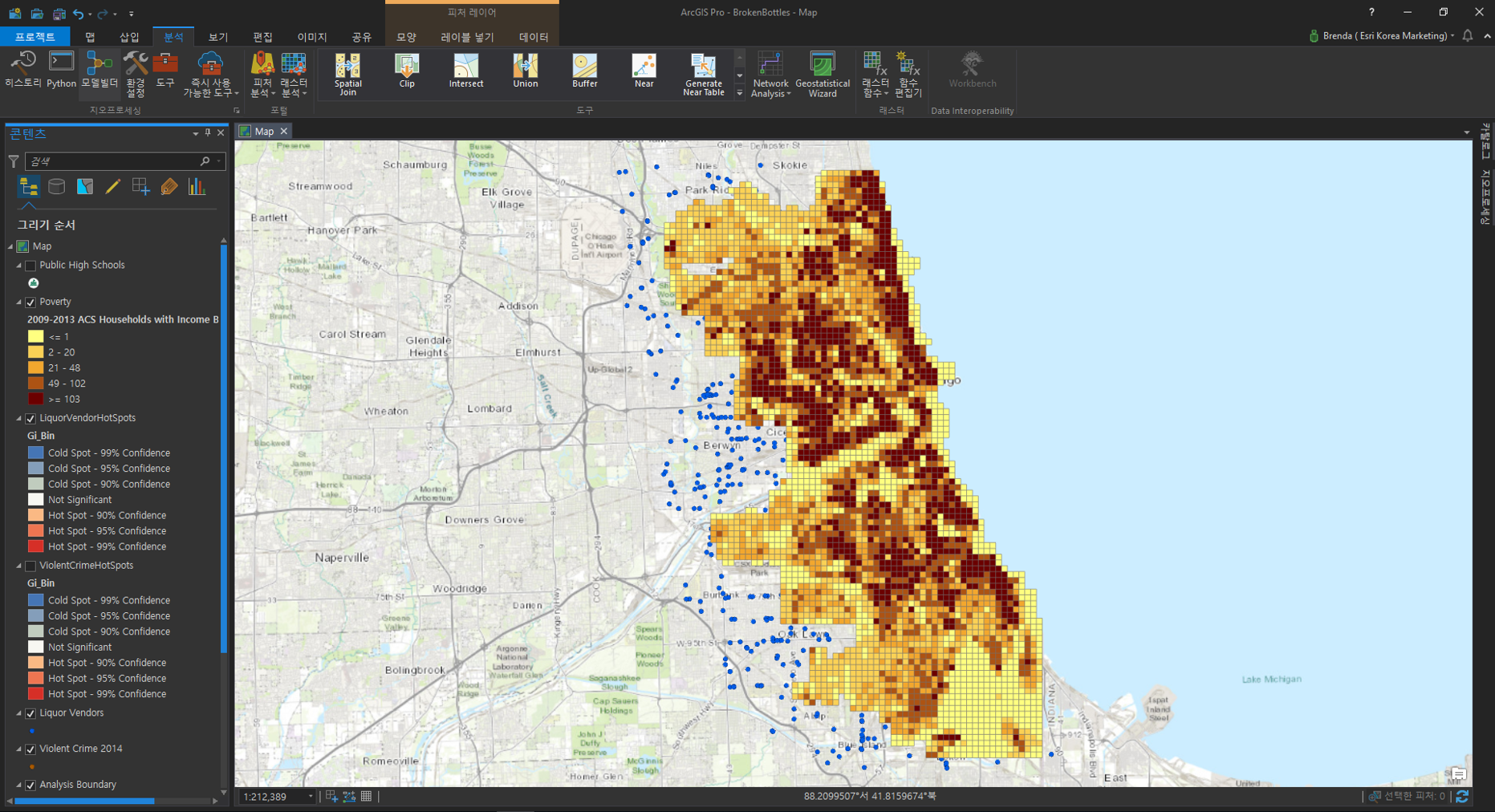
- 입력 피처(Input Features): Poverty
- 결과 피처(Output Feature): 사용자 지정 ex) PovertyHotspots
- 분석 필드(Analysis Field): 2009-2013 ACS Households with Income Below Poverty Level
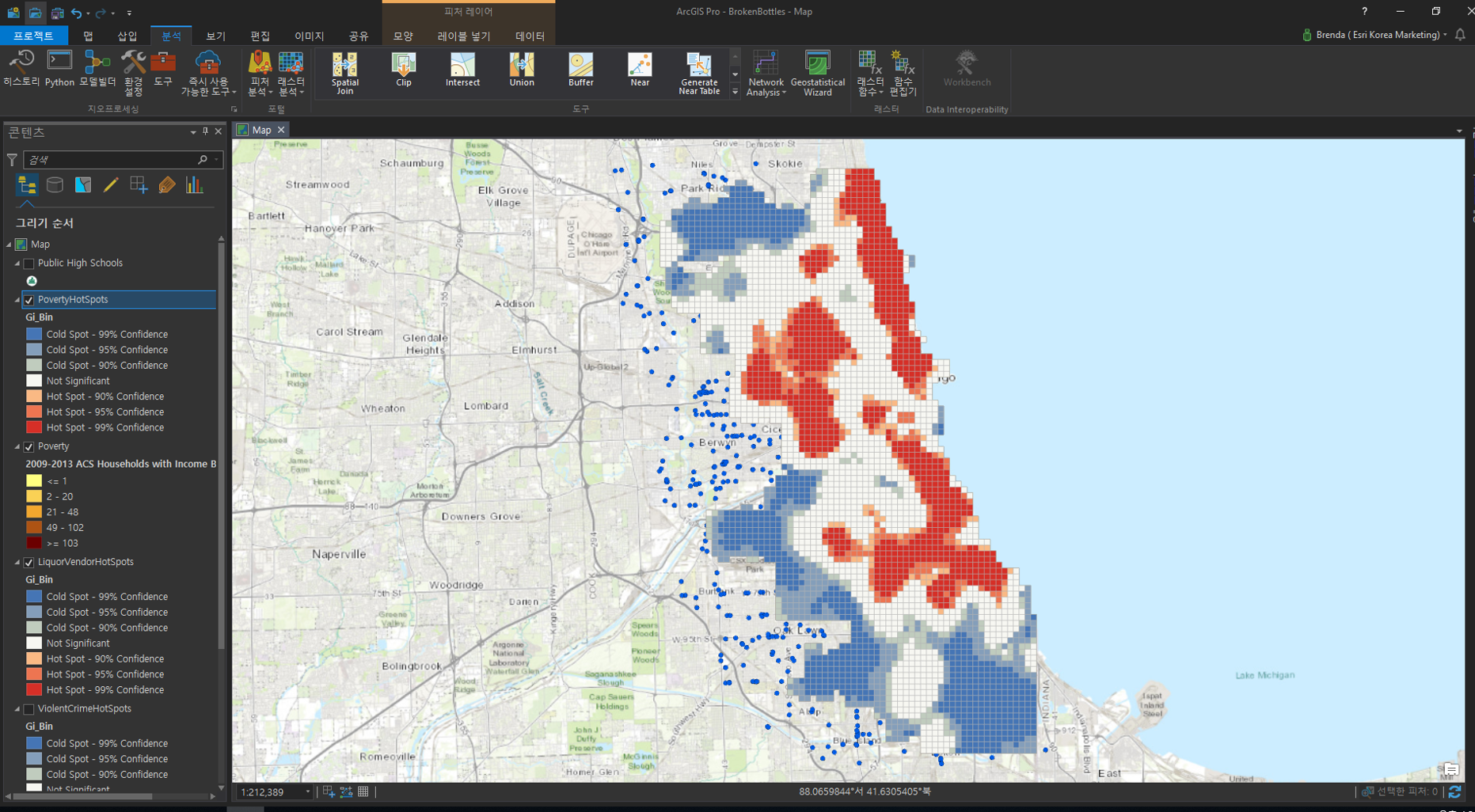
☞ 핫스팟 데이터 중첩을 이용한 영역 결정
이번 단계는 범죄 데이터, 주류 판매점 데이터, 빈곤 데이터에 대해 사건의 발생율이 높은 영역을 선별합니다.
[속성에 의한 레이어 선택(Select Layer By Attribute)]
- 레이어 이름 또는 테이블 뷰(Layer Name or Table View): ViolentCrimeHotSpots
- 선택 유형(Selection Type): 새 선택(New Selection)
- 식(Expression): Gi_Bin fixed 4554_FDR이 3과 같음(Gi_Bin fixed 4554_FDR is equal to 3)
Gi_bin 필드가 3인 레코드는 99% 신뢰구간을 의미하며 이는 사건의 발생율이 높은 지역을 나타냅니다. LiquorVendorHotspots, PovertyHotspots 데이터에 동일한 작업을 수행하면 아래와 같이 결과가 나타납니다.
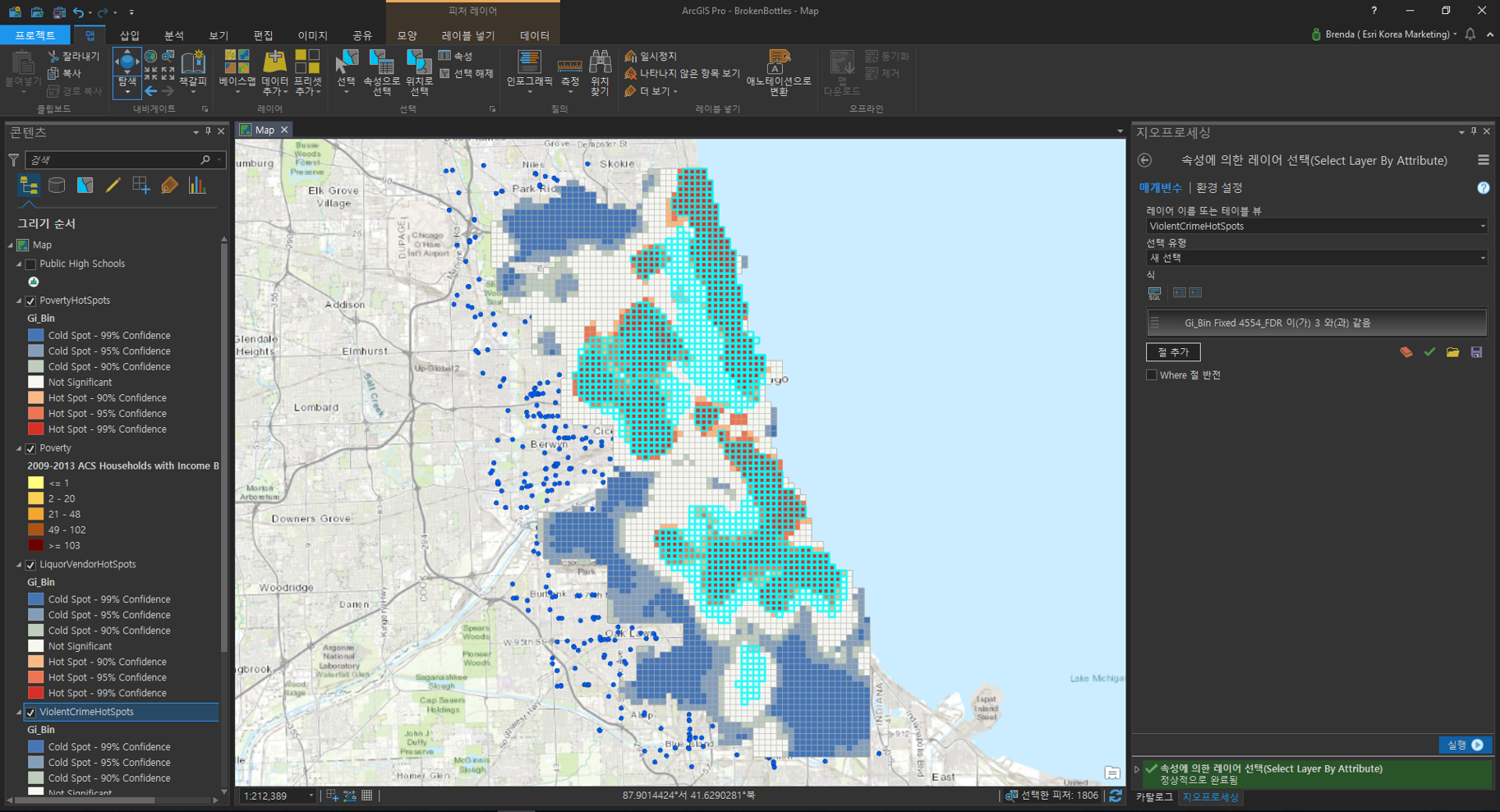
[교차(Intersect)]
- 입력 피처(Input Feature):
– ViolentCrimeHotspots
– LiquorVendorHotspots
– PovertyHotspots - 결과 피처 클래스(Output Feature Class): 사용자 지정 ex) ICrimeLiquorPoverty
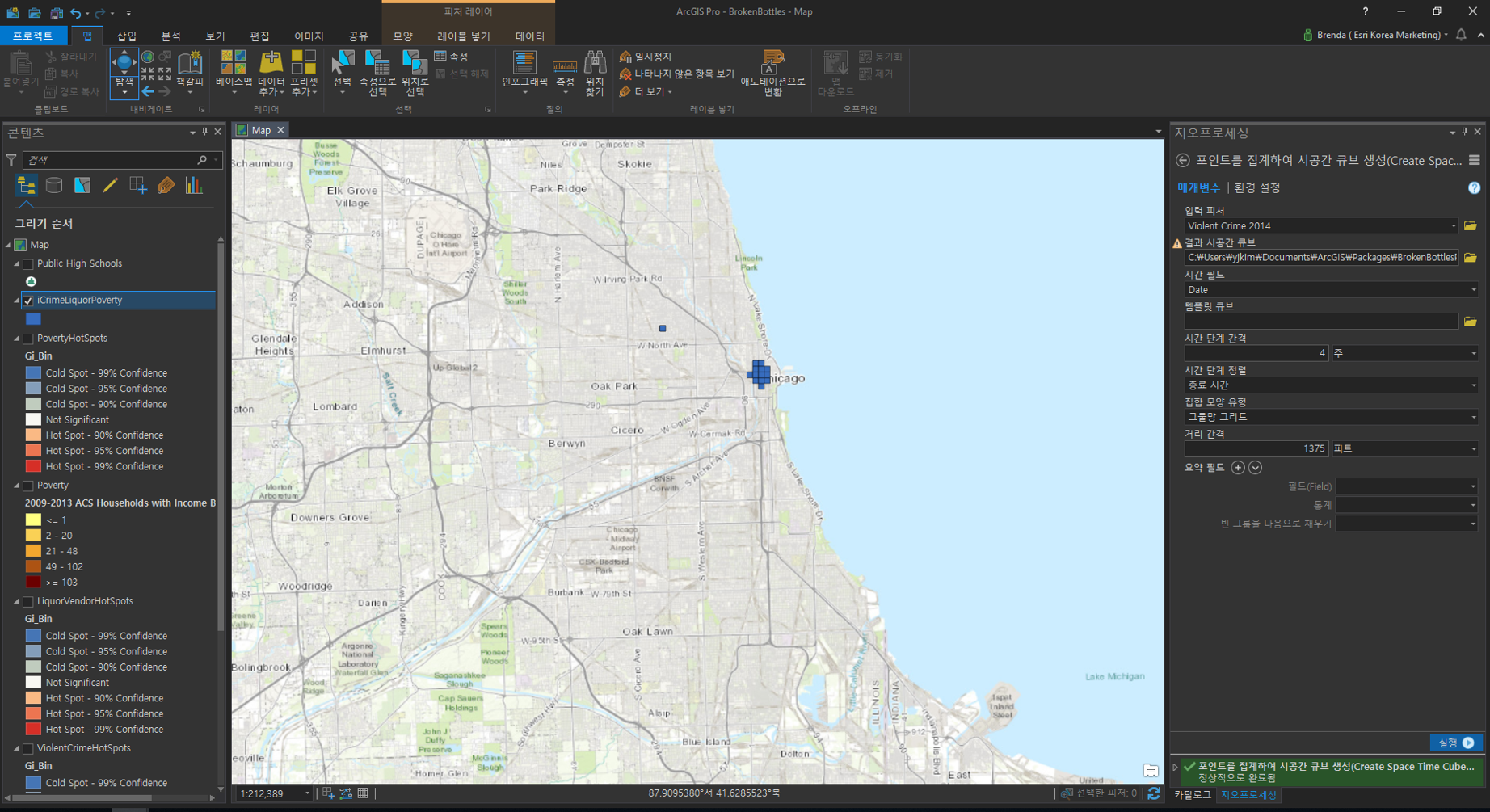
세 가지 데이터에서 선택된 구간을 교차하면 서로 중첩하는 영역만 남게 되는데, 결과 영역이 다소 좁은 것을 확인할 수 있습니다. 즉 범죄, 주류 판매점, 빈곤 데이터 간의 공간적 상관관계가 낮음을 유추할 수 있습니다.
☞ 실업률 데이터 핫스팟 분석 및 사건 발생률 높은 영역 선정
범죄와 실업률의 상관관계를 분석하기 위해 실업률 데이터(Unemployment.lpk)를 불러옵니다.
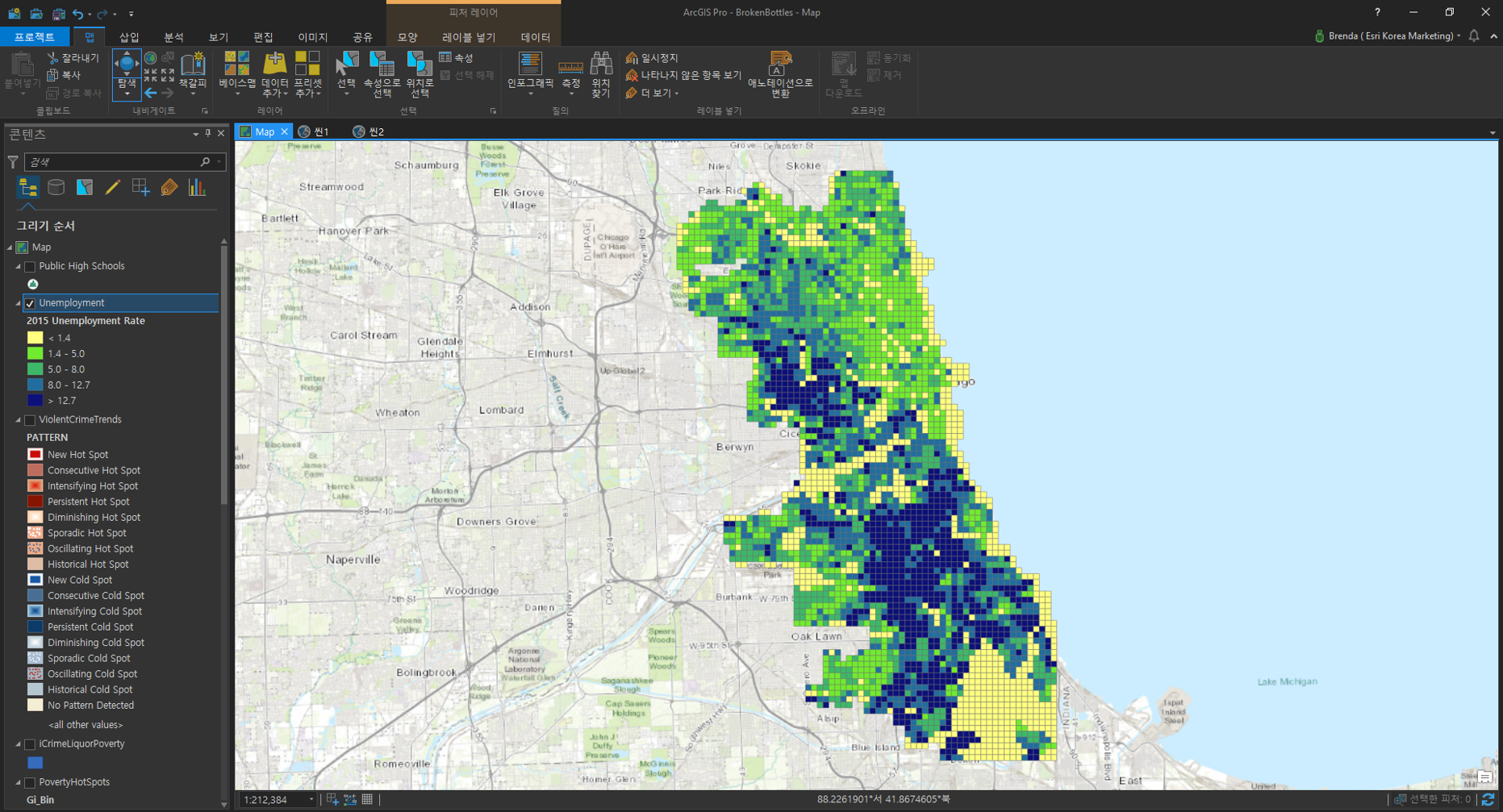
범죄 데이터와 실업률 데이터의 상관관계를 분석하기 위해 이전과 같은 단계를 반복합니다.
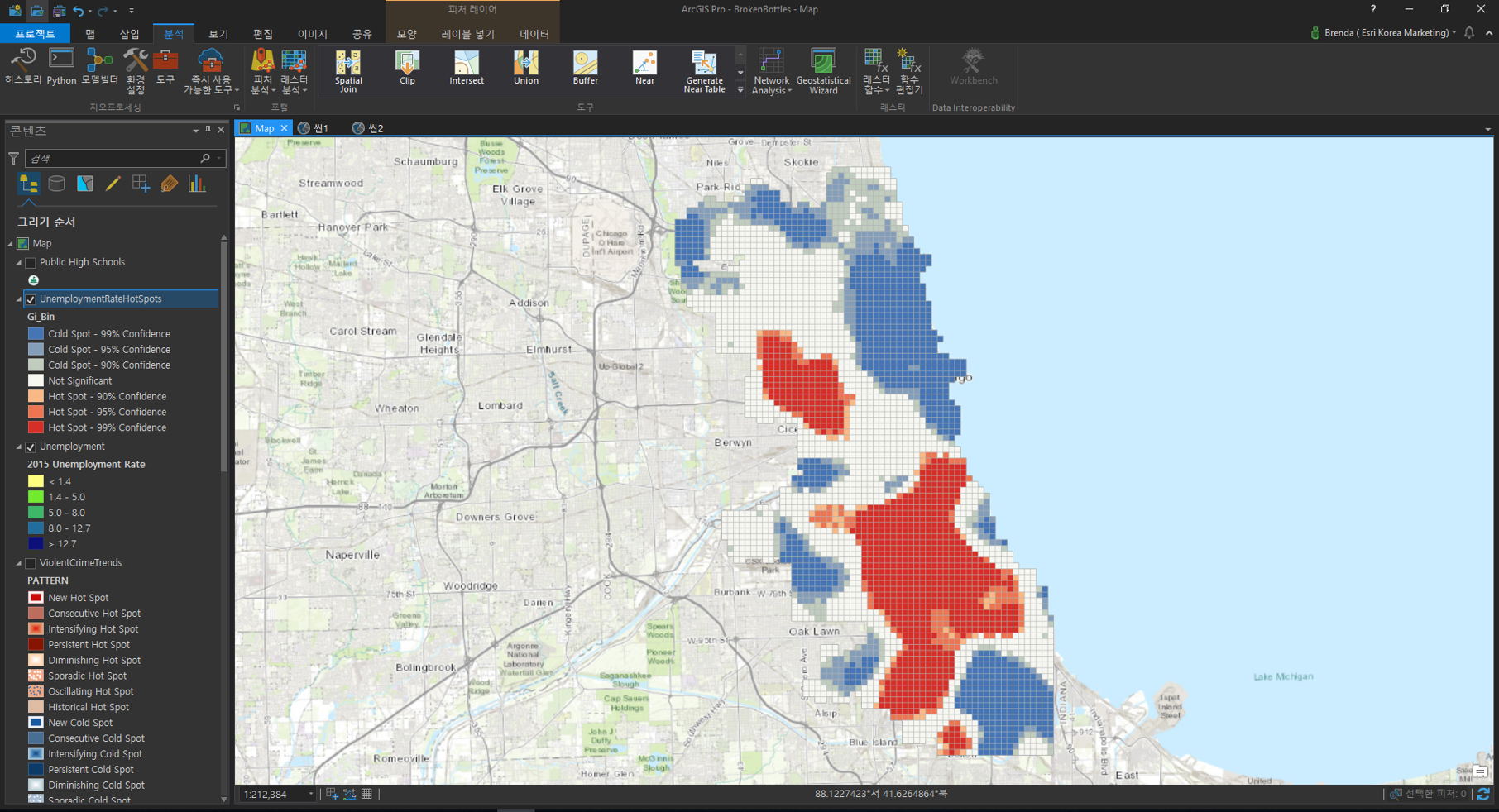
[최적화된 핫스팟 분석(Optimized Hot Spot Analysis)]
- 입력 피처(Input Features): Unemployment
- 결과 피처(Output Feature): 사용자 지정 ex) UnemploymentRateHotSpots
- 분석 필드(Analysis Field): 2015 Unemployment Rate
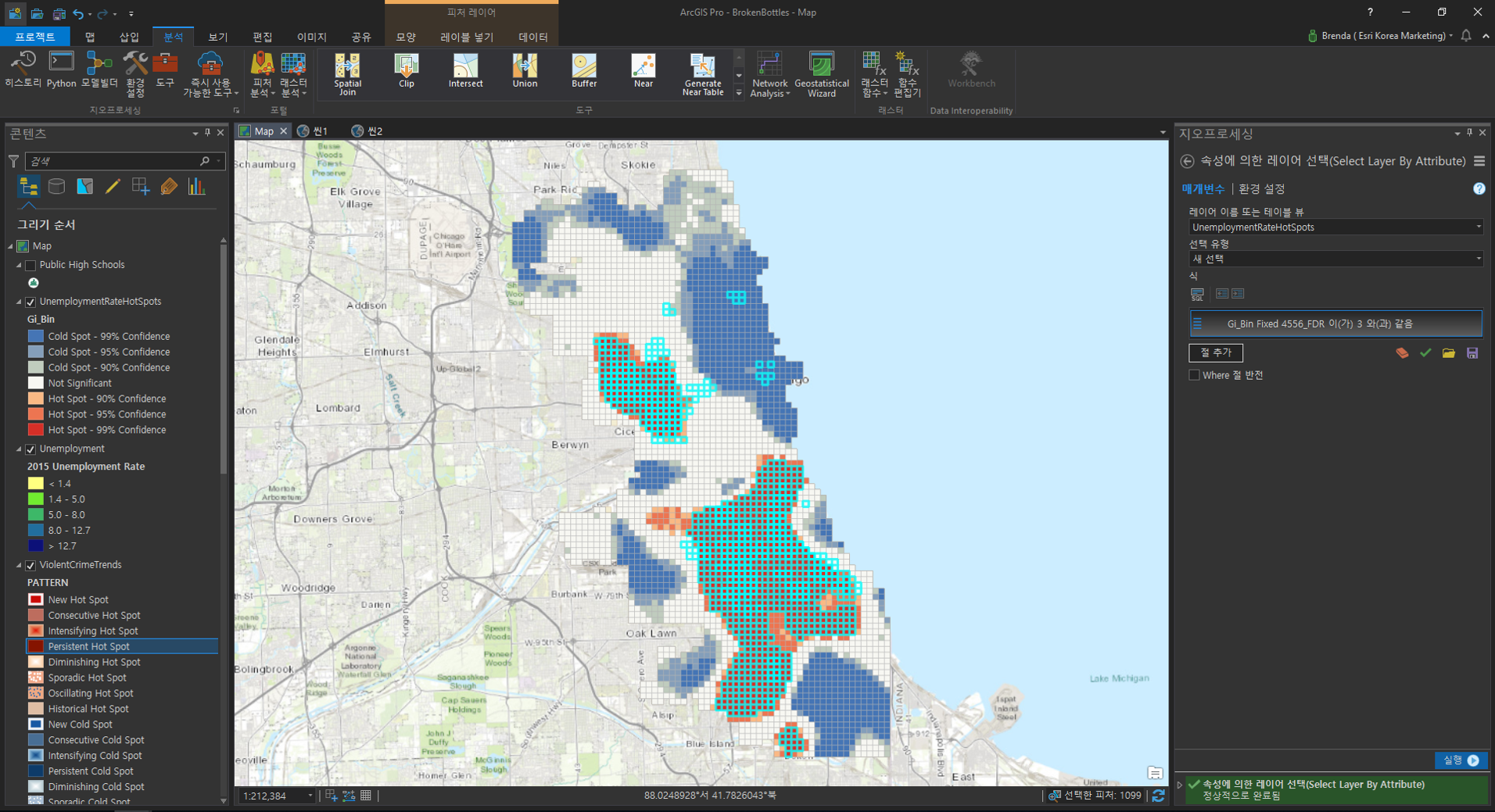
[속성에 의한 레이어 선택(Select Layer By Attribute)]
- 레이어 이름 또는 테이블 뷰(Layer Name or Table View): ViolentCrimeTrends
- 선택 유형(Selection Type): 새 선택(New Selection)
- 식(Expression):
– Pattern Type COUNT는 Consecutive Hot Spot과 같음
– Or Pattern Type COUNT는 Intensifying Hot Spot과 같음
– Or Pattern Type COUNT는 Persistent Hot Spot과 같음 - 레이어 이름 또는 테이블 뷰(Layer Name or Table View): UnemploymentRateHotspots
- 선택 유형(Selection Type): 새 선택(New Selection)
- 식(Expression): Gi_Bin fixed 4554_FDR이 3과 같음
[교차(Intersect)]
- 입력 피처(Input Feature):
– ViolentCrimeHotspots
– UnemploymentRateHotspots - 결과 피처 클래스(Output Feature Class): 사용자 지정 ex) ICrimeUnemp
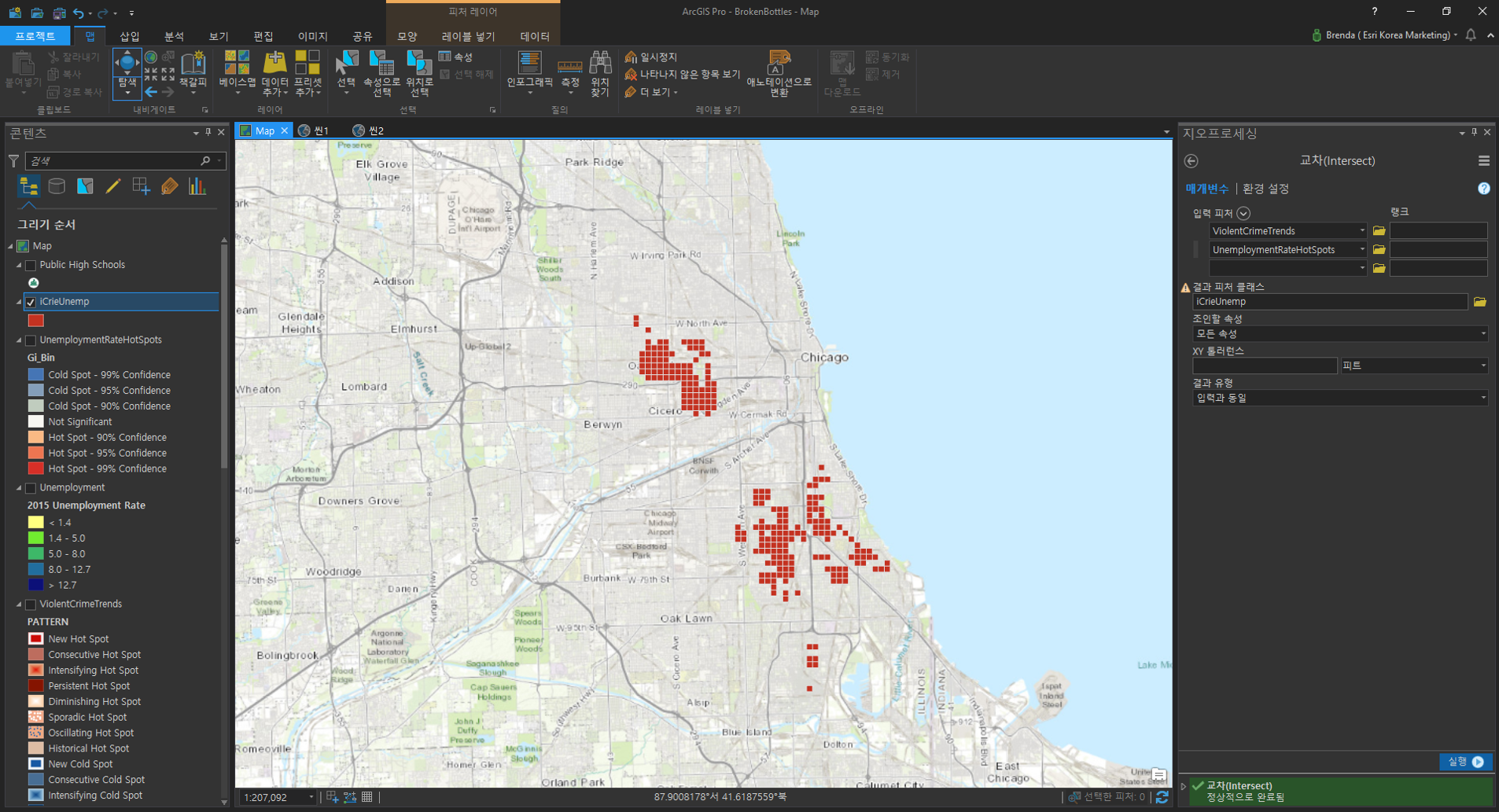
범죄 데이터와 실업률 데이터의 교차 결과는 주류 판매점, 빈곤율에 비해 공간적 상관관계가 높음을 확인할 수 있습니다.
데이터 분석가는 실업률과 범죄의 공간적 상관관계가 가장 유의한다는 결과를 경찰서장에게 전달했습니다. A 지역은 범죄 발생률을 감소시키기 위해 위험 지역 대상으로 여름 직업 프로그램을 시작하였으며, 이는 폭력범죄를 줄이는 데 엄청난 효과가 있음을 증명했다고 합니다.
이 사례에서는 실업률과 범죄의 상관관계가 높은 것으로 분석됐지만, 그렇다고 반드시 실업률이 범죄에 영향을 미친다고 볼 수는 없습니다. 범죄가 발생하는 이유는 다양하고 복잡하기 때문에, 여러 데이터를 이용한 공간분석을 통해 다양한 요소들과의 상관관계를 파악하여 해당 지역만의 주요 이유를 찾아내고 이를 예측, 예방할 수 있습니다.
ArcGIS Pro 완전 정복에서는 총 10개의 콘텐츠를 통해 공간 데이터의 기본 정보부터 공간 분석 사이클을 알아보고 그에 알맞은 실습을 수행해왔습니다. 이제 ArcGIS Pro를 완전히 정복하셨나요? 이 밖에도 ArcGIS Pro는 유틸리티 네트워크 분석, 공간 통계 분석, 시공간 패턴 마이닝 분석 등 다양한 분석을 수행할 수 있습니다. 이번 테크스토리는 ArcGIS Pro 완전정복의 마지막 시리즈로 다음에는 더 유익하고 흥미로운 콘텐츠를 가지고 찾아뵙겠습니다 🙂
연관 게시물 바로 가기
[ArcGIS Pro 완전 정복!] ①입문
[ArcGIS Pro 완전 정복!] ②기본
[ArcGIS Pro 완전 정복!] ③실전: 공유하기
[ArcGIS Pro 완전 정복!] ④분석: 위치에 대한 이해
[ArcGIS Pro 완전 정복!] ⑤분석: 데이터의 관계성을 이용한 분석
[ArcGIS Pro 완전 정복!] ⑥분석: 입지분석
[ArcGIS Pro 완전 정복!] ⑦분석: 고도 데이터를 이용한 가시권 분석
[ArcGIS Pro 완전 정복!] ⑧공간 패턴 분석: 교통사고 데이터를 이용한 핫스팟 분석
[문의] 한국에스리 02)2086-1960
[참고자료] Esri, Analyzing traffic accidents in space and time




댓글 2
안녕하세요! 글 잘 읽었습니다! Gis 과제를 수행하는데 많은 도움이 될 것 같아요! 다름이 아니라 범죄 데이터를 어디서 구하셨는지 알 수 있을까요? ? 과제를 수행하는데 범죄 관련 자세한 데이터를 아무리 찾아봐도 나오지 않아 이렇게 답글 남깁니다..!
안녕하세요 강다현 님,
해당 실습의 데이터는 https://desktop.arcgis.com/en/analytics/case-studies/broken-bottles-3-pro-workflow.htm 페이지에서 Data Package를 다운 받으실 수 있습니다.
감사합니다.